
Abstract: Attribute-based encryption, especially for ciphertext-policy attribute-based encryption, can ful_ll the functionality of _ne-grained access control in cloud storage systems. Since users' attributes may be issued by multiple attribute authorities, multi-authority ciphertext-policy attribute-based encryption is an
emerging cryptographic primitive for enforcing attribute-based access control on outsourced data. However, most of the existing multi-authority attribute-based systems are either insecure in attribute-level revocation or lack of ef_ciency in communication overhead and computation cost. In this paper, we propose an attribute-based access control scheme with two-factor protection for multi-authority cloud storage systems. In our proposed scheme, any user can recover the outsourced data if and only if this user holds suf_cient attribute secret keys with respect to the access policy and authorization key in regard to the outsourced data. In addition, the proposed scheme enjoys the properties of constant-size ciphertext and small computation cost. Besides supporting the attribute-level revocation, our proposed scheme allows data owner to carry out the user-level revocation. The security analysis, performance comparisons, and experimental results indicatethat our proposed scheme is not only secure but also practical.

IEEE 2017: Optimizing Cloud-Service Performance: Efficient Resource Provisioning via Optimal Workload Allocation
Abstract: Abstract—Cloud computing is being widely accepted and utilized in the business world. From the perspective of businesses utilizing the cloud, it is critical to meet their customers’ requirements by achieving service-level-objectives. Hence, the ability to accurately characterize and optimize cloud-service performance is of great importance. In this paper a stochastic multi-tenant framework is proposed to model the service of customer requests in a cloud infrastructure composed of heterogeneous virtual machines. Two cloudservice performance metrics are mathematically characterized, namely the percentile and the mean of the stochastic response time of a customer request, in closed form. Based upon the proposed multi-tenant framework, a workload allocation algorithm, termed maxmin- cloud algorithm, is then devised to optimize the performance of the cloud service. A rigorous optimality proof of the max-min-cloud algorithm is also given. Furthermore, the resource-provisioning problem in the cloud is also studied in light of the max-min-cloud algorithm. In particular, an efficient resource-provisioning strategy is proposed for serving dynamically arriving customer requests. These findings can be used by businesses to build a better understanding of how much virtual resource in the cloud they may need to
meet customers’ expectations subject to cost constraints

Abstract: Recently, big data analytics has received important attention in a variety of application domains including business, finance, space science, healthcare, telecommunication and Internet of Things (IoT). Among these areas, IoT is considered as an important platform in bringing people, processes, data and things/objects together in order to enhance the quality of our everyday lives. However, the key challenges are how to effectively extract useful features from the massive amount of heterogeneous data generated by resource-constrained IoT devices in order to provide real-time information and feedback to the endusers, and how to utilize this data-aware intelligence in enhancing the performance of wireless IoT networks. Although there are parallel advances in cloud computing and edge computing for addressing some issues in data analytics, they have their own benefits and limitations. The convergence of these two computing paradigms, i.e., massive virtually shared pool of computing and storage resources from the cloud and real time data processing by edge computing, could effectively enable live data analytics in wireless IoT networks. In this regard, we propose a novel framework for coordinated processing between edge and cloud computing/processing by integrating advantages from both the platforms. The proposed framework can exploit the network-wide knowledge and historical information available at the cloud center to guide edge computing units towards satisfying various performance requirements of heterogeneous wireless IoT networks. Starting with the main features, key enablers and the challenges of big data analytics, we provide various synergies and distinctions between cloud and edge processing. More importantly, we identify and describe the potential key enablers for the proposed edge-cloud collaborative framework, the associated key challenges and some interesting future research directions.

IEEE 2017: Optimizing Green Energy, Cost, and Availability in Distributed Data Centers
Abstract: Integrating renewable energy and ensuring high availability are among two major requirements for geo distributed data centers. Availability is ensured by provisioning spare capacity across the data centers to mask data center failures (either partial or complete). We propose a mixed integer linear programming formulation for capacity planning while minimizing the total cost of ownership (TCO) for highly available, green, distributed data centers. We minimize the cost due to power consumption and server deployment, while targeting a minimum usage of green energy. Solving our model shows that capacity provisioning considering green energy integration, not only lowers carbon footprint but also reduces the TCO. Results show that up to 40% green energy usage is feasible with marginal increase in the TCO compared to the other cost-aware models.

IEEE 2017: Cost Minimization Algorithms for Data Center Management
Abstract: Due to the increasing usage of cloud computing applications, it is important to minimize energy cost consumed by a data center, and simultaneously, to improve quality of service via data center management. One promising approach is to switch some servers in a data center to the idle mode for saving energy while to keep a suitable number of servers in the active mode for providing timely service. In this paper, we design both online and offline algorithms for this problem. For the offline algorithm, we formulate data center management as a cost minimization problem by considering energy cost, delay cost (to measure service quality), and switching cost (to change servers’ active/idle mode). Then, we analyze certain properties of an optimal solution which lead to a dynamic programming based algorithm. Moreover, by revising the solution procedure, we successfully eliminate the recursive procedure and achieve an optimal offline algorithm with a polynomial complexity.

IEEE 2017: Vehicular Cloud Data Collection for Intelligent Transportation Systems
Abstract: The Internet of Things (IoT) envisions to connect billions of sensors to the Internet, in order to provide new applications and services for smart cities. IoT will allow the evolution of the Internet of Vehicles (IoV) from existing Vehicular Ad hoc Networks (VANETs), in which the delivery of various services will be offered to drivers by integrating vehicles, sensors, and mobile devices into a global network. To serve VANET with computational resources, Vehicular Cloud Computing (VCC) is recently envisioned with the objective of providing traffic solutions to improve our daily driving. These solutions involve applications and services for the benefit of Intelligent Transportation Systems (ITS), which represent an important part of IoV. Data collection is an important aspect in ITS, which can effectively serve online travel systems with the aid of Vehicular Cloud (VC). In this paper, we involve the new paradigm of VCC to propose a data collection model for the benefit of ITS. We show via simulation results that the participation of low percentage of vehicles in a dynamic VC is sufficient to provide meaningful data collection.

IEEE 2017: RAAC: Robust and Auditable Access Control with Multiple Attribute Authorities for Public Cloud Storage
Abstract: Data access control is a challenging issue in public cloud storage systems. Ciphertext-Policy Attribute-Based En-cryption (CP-ABE) has been adopted as a promising technique to provide flexible, fine-grained and secure data access control for cloud storage with honest-but-curious cloud servers. However, in the existing CP-ABE schemes, the single attribute authority must execute the time-consuming user legitimacy verification and secret key distribution, and hence it results in a single-point performance bottleneck when a CP-ABE scheme is adopted in a large-scale cloud storage system. Users may be stuck in the waiting queue for a long period to obtain their secret keys, thereby resulting in low-efficiency of the system. Although multi-authority access control schemes have been proposed, these schemes still cannot overcome the drawbacks of single-point bottleneck and low efficiency, due to the fact that each of the authorities still independently manages a disjoint attribute set.

IEEE 2017: Privacy-Preserving Data Encryption Strategy for Big Data in Mobile Cloud Computing
Abstract: Privacy has become a considerable issue when the applications of big data are dramatically growing in cloud computing. The benefits of the implementation for these emerging technologies have improved or changed service models and improve application performances in various perspectives. However, the remarkably growing volume of data sizes has also resulted in many challenges in practice. The execution time of the data encryption is one of the serious issues during the data processing and transmissions. Many current applications abandon data encryptions in order to reach an adoptive performance level companioning with privacy concerns. In this paper, we concentrate on privacy and propose a novel data encryption approach, which is called Dynamic Data Encryption Strategy (D2ES). Our proposed approach aims to selectively encrypt data and use privacy classification methods under timing constraints. This approach is designed to maximize the privacy protection scope by using a selective encryption strategy within the required execution time requirements.

IEEE 2017: Identity-Based Remote Data Integrity Checking With Perfect Data Privacy Preserving for Cloud Storage
Abstract: Remote data integrity checking (RDIC) enables a data storage server, says a cloud server, to prove to a verifier that it is actually storing a data owner’s data honestly. To date, a number of RDIC protocols have been proposed in the literature, but most of the constructions suffer from the issue of a complex key management, that is, they rely on the expensive public key infrastructure (PKI), which might hinder the deployment of RDIC in practice. In this paper, we propose a new construction of identity-based (ID-based) RDIC protocol by making use of key- homomorphic cryptographic primitive to reduce the system complexity and the cost for establishing and managing the public key authentication framework in PKI-based RDIC schemes. We formalize ID-based RDIC and its security model, including security against a malicious cloud server and zero knowledge privacy against a third party verifier. The proposed ID-based RDIC protocol leaks no information of the stored data to the verifier during the RDIC process. The new construction is proven secure against the malicious server in the generic group model and achieves zero knowledge privacy against a verifier. Extensive security analysis and implementation results demonstrate that the proposed protocol is provably secure and practical in the real-world applications

IEEE 2017: Identity-Based Data Outsourcing with Comprehensive Auditing in Clouds
Abstract: Cloud storage system provides facilitative file storage and sharing services for distributed clients. To address integrity, controllable outsourcing and origin auditing concerns on outsourced files, we propose an identity-based data outsourcing (IBDO) scheme equipped with desirable features advantageous over existing proposals in securing outsourced data. First, our IBDO scheme allows a user to authorize dedicated proxies to upload data to the cloud storage server on her behalf, e.g., a company may authorize some employees to upload files to the company’s cloud account in a controlled way. The proxies are identified and authorized with their recognizable identities, which eliminates complicated certificate management in usual secure distributed computing systems. Second, our IBDO scheme facilitates comprehensive auditing, i.e., our scheme not only permits regular integrity auditing as in existing schemes for securing outsourced data, but also allows to audit the information on data origin, type and consistence of outsourced files.

IEEE 2017: TAFC: Time and Attribute Factors Combined Access Control on Time-Sensitive Data in Public Cloud
Abstract: The new paradigm of outsourcing data to the cloud is a double-edged sword. On one side, it frees up data owners from the technical management, and is easier for the data owners to share their data with intended recipients when data are stored in the cloud. On the other side, it brings about new challenges about privacy and security protection. To protect data confidentiality against the honest-but-curious cloud service provider, numerous works have been proposed to support fine-grained data access control. However, till now, no efficient schemes can provide the scenario of fine-grained access control together with the capacity of time-sensitive data publishing. In this paper, by embedding the mechanism of timed-release encryption into CP-ABE (Ciphertext- Policy Attribute-based Encryption), we propose TAFC: a new time and attribute factors combined access control on time sensitive data stored in cloud. Extensive security and performance analysis shows that our proposed scheme is highly efficient and
satisfies the security requirements for time-sensitive data storage in public cloud.

IEEE 2017: Attribute-Based Storage Supporting Secure Deduplication of Encrypted Data in Cloud
Abstract: Attribute-based encryption (ABE) has been widely used in cloud computing where a data provider outsources his/her encrypted data to a cloud service provider, and can share the data with users possessing specific credentials (or attributes). However, the standard ABE system does not support secure deduplication, which is crucial for eliminating duplicate copies of identical data in order to save storage space and network bandwidth. In this paper, we present an attribute-based storage system with secure deduplication in a hybrid cloud setting, where a private cloud is responsible for duplicate detection and a public cloud manages the storage. Compared with the prior data deduplication systems, our system has two advantages. Firstly, it can be used to confidentially share data with users by specifying access policies rather than sharing decryption keys. Secondly, it achieves the standard notion of semantic security for data confidentiality while existing systems only achieve it by defining a weaker security notion.

IEEE 2017: A Collision-Mitigation Cuckoo Hashing Scheme for Large-scale Storage Systems
Abstract: With the rapid growth of the amount of information, cloud computing servers need to process and analyze large amounts of high-dimensional and unstructured data timely and accurately. This usually requires many query operations. Due to simplicity and ease of use, cuckoo hashing schemes have been widely used in real-world cloud-related applications. However due to the potential hash collisions, the cuckoo hashing suffers from endless loops and high insertion latency, even high risks of re-construction of entire hash table. In order to address these problems, we propose a cost-efficient cuckoo hashing scheme, called MinCounter. The idea behind MinCounter is to alleviate the occurrence of endless loops in the data insertion by selecting unbusy kicking-out routes. MinCounter selects the “cold” (infrequently accessed), rather than random, buckets to handle hash collisions. We further improve the concurrency of the MinCounter scheme to pursue higher performance and adapt to concurrent applications. MinCounter has the salient features of offering efficient insertion and query services and delivering high performance of cloud servers, as well as enhancing the experiences for cloud users. We have implemented MinCounter in a large-scale cloud test bed and examined the performance by using three real-world traces. Extensive experimental results demonstrate the efficacy and efficiency of MinCounter.

IEEE 2016: Reducing Fragmentation for In-line Deduplication Backup Storage via Exploiting Backup History and Cache Knowledge
Abstract: In backup systems, the chunks of each backup are physically scattered after deduplication, which causes a challenging fragmentation problem. We observe that the fragmentation comes into sparse and out-of-order containers. The sparse container decreases restore performance and garbage collection efficiency, while the out-of-order container decreases restore performance if the restore cache is small. In order to reduce the fragmentation, we propose History-Aware Rewriting algorithm (HAR) and Cache-Aware Filter (CAF). HAR exploits historical information in backup systems to accurately identify and reduce sparse containers, and CAF exploits restore cache knowledge to identify the out-of-order containers that hurt restore performance. CAF efficiently complements HAR in datasets where out-of-order containers are dominant. To reduce the metadata overhead of the garbage collection, we further propose a Container-Marker Algorithm (CMA) to identify valid containers instead of valid chunks. Our extensive experimental results from real-world datasets show HAR significantly improves the restore performance by 2.84-175.36 × at a cost of only rewriting 0.5-2.03 percent data.

IEEE 2016: Secure Data Sharing in Cloud Computing Using Revocable-Storage Identity-Based Encryption
Abstract: Cloud computing provides a flexible and convenient way for data sharing, which brings various benefits for both the society and individuals. But there exists a natural resistance for users to directly outsource the shared data to the cloud server since the data often contain valuable information. Thus, it is necessary to place cryptographically enhanced access control on the shared data. Identity-based encryption is a promising cryptographical primitive to build a practical data sharing system. However, access control is not static. That is, when some user’s authorization is expired, there should be a mechanism that can remove him/her from the system. Consequently, the revoked user cannot access both the previously and subsequently shared data. To this end, we propose a notion called revocable-storage identity-based encryption (RS-IBE), which can provide the forward/backward security of cipher text by introducing the functionalities of user revocation and cipher text update simultaneously. Furthermore, we present a concrete construction of RS-IBE, and prove its security in the defined security model. The performance comparisons indicate that the proposed RS-IBE scheme has advantages in terms of functionality and efficiency, and thus is feasible for a practical and cost-effective data-sharing system. Finally, we provide implementation results of the proposed scheme to demonstrate its practicability.

IEEE 2016: Key-Aggregate Searchable Encryption (KASE) for Group Data Sharing via Cloud Storage
Abstract: The capability of selectively sharing encrypted data with different users via public cloud storage may greatly ease security concerns over inadvertent data leaks in the cloud. A key challenge to designing such encryption schemes lies in the efficient management of encryption keys. The desired flexibility of sharing any group of selected documents with any group of users demands different encryption keys to be used for different documents. However, this also implies the necessity of securely distributing to users a large number of keys for both encryption and search, and those users will have to securely store the received keys, and submit an equally large number of keyword trapdoors to the cloud in order to perform search over the shared data. The implied need for secure communication, storage, and complexity clearly renders the approach impractical. In this paper, we address this practical problem, which is largely neglected in the literature, by proposing the novel concept of key-aggregate search able encryption and instantiating the concept through a concrete KASE scheme, in which a data owner only needs to distribute a single key to a user for sharing a large number of documents, and the user only needs to submit a single trapdoor to the cloud for querying the shared documents. The security analysis and performance evaluation both confirm that our proposed schemes are provably secure and practically efficient.

IEEE 2016: Public Integrity Auditing for Shared Dynamic Cloud Data with Group User Revocation
Abstract: The advent of the cloud computing makes storage outsourcing becomes a rising trend, which promotes the secure remote data auditing a hot topic that appeared in the research literature. Recently some research considers the problem of secure and efficient public data integrity auditing for shared dynamic data. However, these schemes are still not secure against the collusion of cloud storage server and revoked group users during user revocation in practical cloud storage system. In this paper, we figure out the collusion attack in the exiting scheme and provide an efficient public integrity auditing scheme with secure group user revocation based on vector commitment and verifier-local revocation group signature. We design a concrete scheme based on the our scheme definition. Our scheme supports the public checking and efficient user revocation and also some nice properties, such as confidently, efficiency, countability and traceability of secure group user revocation. Finally, the security and experimental analysis show that, compared with its relevant schemes our scheme is also secure and efficient.

IEEE 2016: Secure Auditing and Duplicating Data in Cloud
Abstract: As the cloud computing technology develops during the last decade outsourcing data to cloud service for storage becomes an attractive trend, which benefits in sparing efforts on heavy data maintenance and management. Nevertheless, since the outsourced cloud storage is not fully trustworthy, it raises security concerns on how to realize data deduplication in cloud while achieving integrity auditing. In this work, we study the problem of integrity auditing and secure deduplication on cloud data. Specifically, aiming at achieving both data integrity and deduplication in cloud, we propose two secure systems, namely Sec Cloud and Sec Cloud . Sec Cloud introduces an auditing entity with a maintenance of a Map Reduce cloud, which helps clients generate data tags before uploading as well as audit the integrity of data having been stored in cloud. Compared with previous work, the computation by user in Sec Cloud greatly reduced during the file uploading and auditing phases. Sec Cloud is designed motivated by the fact that customers always want to encrypt their data before uploading, and enables integrity auditing and secure deduplication on encrypted data.

IEEE 2015 TRANSACTIONS ON COMPUTERS
Abstract : Data deduplication is a technique for eliminating duplicate copies of data, and
has been widely used in cloud storage to reduce storage space and upload
bandwidth. However, there is only one copy for each file stored in cloud even
if such a file is owned by a huge number of users. As a result, deduplication system
improves storage utilization while reducing reliability. Furthermore, the
challenge of privacy for sensitive data also arises when they are outsourced by
users to cloud. Aiming to address the above security challenges, this paper
makes the first attempt to formalize the notion of distributed reliable
deduplication system. We propose new distributed deduplication systems with
higher reliability in which the data chunks are distributed across multiple
cloud servers. The security requirements of data confidentiality and tag
consistency are also achieved by introducing a deterministic secret sharing
scheme in distributed storage systems, instead of using convergent encryption
as in previous deduplication systems. Security analysis demonstrates that our
deduplication systems are secure in terms of the definitions specified in the
proposed security model. As a proof of concept, we implement the proposed
systems and demonstrate that the incurred overhead is very limited in realistic
environments.

IEEE 2015 : Control Cloud Data Access Privilege and Anonymity With Fully Anonymous Attribute-Based Encryption
IEEE 2015 TRANSACTIONS ON COMPUTERS
Abstract :Cloud
computing is a revolutionary computing paradigm, which
enables flexible, on-demand, and low-cost usage of computing
resources, but the data is outsourced to some cloud servers, and
various privacy concerns emerge from it. Various schemes based
on the attribute-based encryption have been proposed to
secure the cloud storage. However, most work focuses on the data
contents privacy and the access control, while less attention
is paid to the privilege control and the identity privacy. In
this paper, we present a semianonymous privilege control
scheme AnonyControl to address not only the data privacy, but
also the user identity privacy in existing access control schemes.
AnonyControl decentralizes the central authority to limit the identity
leakage and thus achieves semianonymity. Besides, it also generalizes the file
access control to the privilege control, by which
privileges of all operations on the cloud data can be managed in a
fine-grained manner. Subsequently, we present the
AnonyControl-F, which fully prevents the identity leakage and achieve
the full anonymity. Our security analysis shows that both
AnonyControl and AnonyControl-F are secure under the decisional
bilinear Diffie–Hellman assumption, and our performance
evaluation exhibits the feasibility of our schemes.

IEEE 2015 TRANSACTIONS ON COMPUTERS
Abstract :Media streaming applications have recently attracted a large number of users in the Internet. With the advent of these bandwidth-intensive applications, it is economically inefficient to provide streaming distribution with guaranteed QoS relying only on central resources at a media content provider. Cloud computing offers an elastic infrastructure that media content providers (e.g., Video on Demand (VoD) providers) can use to obtain streaming resources that match the demand. Media content providers are charged for the amount of resources allocated (reserved) in the cloud. Most of the existing cloud providers employ a pricing model for the reserved resources that is based on non-linear time-discount tariffs (e.g., Amazon CloudFront and Amazon EC2). Such a pricing scheme offers discount rates depending non-linearly on the period of time during which the resources are reserved in the cloud. In this case, an open problem is to decide on both the right amount of resources reserved in the cloud, and their reservation time such that the financial cost on the media content provider is minimized.We propose a simple - easy to implement - algorithm for resource reservation that maximally exploits discounted rates offered in the tariffs, while ensuring that sufficient resources are reserved in the cloud. Based on the prediction of demand for streaming capacity, our algorithm is carefully designed to reduce the risk of making wrong resource allocation decisions. The results of our numerical evaluations and simulations show that the proposed algorithm significantly reduces the monetary cost of resource allocations in the cloud as compared to other conventional schemes.

IEEE 2015 : OPoR - Enabling Proof of Retrievability in Cloud Computing with Resource-Constrained Devices
IEEE 2015 TRANSACTIONS ON COMPUTERS

IEEE 2015 : Reducing Fragmentation for In-line Deduplication Backup Storage via Exploiting Backup History And Cache Knowledge
IEEE 2015 TRANSACTIONS ON COMPUTERS
Abstract : In backup systems, the chunks of each backup
are physically scattered after deduplication, which causes a challenging
fragmentation problem. We observe that the fragmentation comes into sparse and
out-of-order containers. The sparse container decreases restore performance and
garbage collection efficiency, while the out-of-order container decreases
restore performance if the restore cache is small. In order to reduce the
fragmentation, we propose History-Aware Rewriting algorithm (HAR) and
Cache-Aware Filter (CAF). HAR exploits historical information in backup systems
to accurately identify and reduce sparse containers, and CAF exploits restore
cache knowledge to identify the out-of-order containers that hurt restore
performance. CAF efficiently complements HAR in datasets where out-of-order
containers are dominant. To reduce the metadata overhead of the garbage
collection, we further propose a Container-Marker Algorithm (CMA) to identify
valid containers instead of valid chunks. Our extensive experimental results
from real-world datasets show HAR significantly improves the restore
performance by 2.84-175.36at a cost of only rewriting 0.5-2.03% data.
IEEE 2015 : Secure Distributed Deduplication Systems with Improved Reliability
IEEE 2015 TRANSACTIONS ON COMPUTERS
Abstract : Data deduplication is a technique for eliminating duplicate copies of data, and has been widely used in cloud storage to reduce storage space and upload bandwidth. However, there is only one copy for each file stored in cloud even if such a file is owned by a huge number of users. As a result, deduplication system improves storage utilization while reducing reliability. Furthermore, the challenge of privacy for sensitive data also arises when they are outsourced by users to cloud. Aiming to address the above security challenges, this paper makes the first attempt to formalize the notion of distributed reliable deduplication system. We propose new distributed deduplication systems with higher reliability in which the data chunks are distributed across multiple cloud servers. The security requirements of data confidentiality and tag consistency are also achieved by introducing a deterministic secret sharing scheme in distributed storage systems, instead of using convergent encryption as in previous deduplication systems. Security analysis demonstrates that our deduplication systems are secure in terms of the definitions specified in the proposed security model. As a proof of concept, we implement the proposed systems and demonstrate that the incurred overhead is very limited in realistic environments.

IEEE 2015 : Enabling Efficient Multi-Keyword Ranked Search Over Encrypted Mobile Cloud Data Through Blind Storage
IEEE 2015 TRANSACTIONS ON COMPUTERS
Abstract : In mobile cloud computing, a fundamental application is to outsource the mobile data to external cloud servers for scalable data storage. The outsourced data, however, need to be encrypted due to the privacy and con dentiality concerns of their owner. This results in the distinguished dif culties on the accurate search over the encrypted mobile cloud data. To tackle this issue, in this paper, we develop the searchable encryption for multi-keyword ranked search over the storage data. Speci cally, by considering the large number of outsourced documents (data) in the cloud, we utilize the relevance score and k-nearest neighbor techniques to develop an ef cient multi-keyword search scheme that can return the ranked search results based on the accuracy. Within this framework, we leverage an ef cient index to further improve the search ef ciency, and adopt the blind storage system to conceal access pattern of the search user. Security analysis demonstrates that our scheme can achieve con dentiality of documents and index, trapdoor privacy, trapdoor unlinkability, and concealing access pattern of the search user. Finally, using extensive simulations, we show that our proposal can achieve much improved ef ciency in terms of search functionality and search time compared with the existing proposals.

Governance Model for Cloud Computing in Building Information Management
IEEE 2015 TRANSACTIONS ON COMPUTERS
Abstract : The AEC (Architecture Engineering and Construction) sector is a highly fragmented, data intensive, project based industry, involving a number or very different professions and organisations. The industry’s strong data sharing and processing requirements means that the management of building data is complex and challenging.We present a data sharing capability utilising Cloud Computing, with two key contributions: 1) a governance model for building data, based on extensive research and industry consultation. This governance model describes how individual data artefacts within a building information model relate to each other and how access to this data is controlled; 2) a prototype implementation of this governance model, utilising the CometCloud autonomic cloud computing engine, using the Master/Work paradigm. This prototype is able to successfully store and manage building data, provide security based on a defined policy language and demonstrate scale-out in case of increasing demand or node failure. Our prototype is evaluated both qualitatively and quantitatively. To enable this evaluation we have integrated our prototype with the 3D modelling softwareVGoogle Sketchup. We also evaluate the prototype’s performance when scaling to utilise additional nodes in the Cloud and to determine its performance in case of node failures.

Secure Sensitive Data Sharing on a Big Data Platform
IEEE 2015 TRANSACTIONS ON COMPUTERS
Abstract: Users store vast amounts of sensitive data on a big data platform. Sharing sensitive data will help enterprises reduce the cost of providing users with personalized services and provide value-added data services.However, secure data sharing is problematic. This paper proposes a framework for secure sensitive data sharing on a big data platform, including secure data delivery, storage, usage, and destruction on a semi-trusted big data sharing platform. We present a proxy re-encryption algorithm based on heterogeneous ciphertext transformation and a user process protection method based on a virtual machine monitor, which provides support for the realization of system functions. The framework protects the security of users’ sensitive data effectively and shares these data safely. At the same time, data owners retain complete control of their own data in a sound environment for modern Internet information security.

Just-in-Time Code Offloading for Wearable Computing
IEEE 2015 TRANSACTIONS ON COMPUTERS
ABSTRACT : Wearable computing becomes an emerging computing paradigm for various recently developed wearable devices, such as Google Glass and the Samsung Galaxy Smartwatch, which have signi cantly changed our daily life with new functions. To magnify the applications on wearable devices with limited computational capability, storage, and battery capacity, in this paper, we propose a novel three-layer architecture consisting of wearable devices, mobile devices, and a remote cloud for code of oad-ing. In particular, we of oad a portion of computation tasks from wearable devices to local mobile devices or remote cloud such that even applications with a heavy computation load can still be upheld on wearable devices. Furthermore, considering the special characteristics and the requirements of wearable devices, we investigate a code of oading strategy with a novel just-in-time objective, i.e., maximizing the number of tasks that should be executed on wearable devices with guaranteed delay requirements. Because of the NP-hardness of this problem as we prove, we propose a fast heuristic algorithm based on the genetic algorithm to solve it. Finally, extensive simulations are conducted to show that our proposed algorithm signi cantly outperforms the other three of loading strategies.

Panda: Public Auditing for Shared Data with Efficient User Revocation in the Cloud
IEEE 2015 TRANSACTIONS ON COMPUTERS
Abstract—With data storage and sharing services in the cloud, users can easily modify and share data as a group. To ensure shared data integrity can be verified publicly, users in the group need to compute signatures on all the blocks in shared data. Different blocks in shared data are generally signed by different users due to data modifications performed by different users. For security reasons, once a user is revoked from the group, the blocks which were previously signed by this revoked user must be re-signed by an existing user. The straightforward method, which allows an existing user to download the corresponding part of shared data and re-sign it during user revocation, is inefficient due to the large size of shared data in the cloud. In this paper, we propose a novel public auditing mechanism for the integrity of shared data with efficient user revocation in mind. By utilizing the idea of proxy re-signatures, we allow the cloud to re-sign blocks on behalf of existing users during user revocation, so that existing users do not need to download and re-sign blocks by themselves. In addition, a public verifier is always able to audit the integrity of shared data without retrieving the entire data from the cloud, even if some part of shared data has been re-signed by the cloud. Moreover, our mechanism is able to support batch auditing by verifying multiple auditing tasks simultaneously. Experimental results show that our mechanism can significantly improve the efficiency of user revocation.

Toward Offering More Useful Data Reliably to Mobile Cloud From Wireless Sensor Network
IEEE 2015 TRANSACTIONS ON COMPUTERS
ABSTRACT : The integration of ubiquitous wireless sensor network (WSN) and powerful mobile cloud computing (MCC) is a research topic that is attracting growing interest in both academia and industry. In this new paradigm, WSN provides data to the cloud and mobile users request data from the cloud. To support applications involving WSN-MCC integration, which need to reliably offer data that are more useful to the mobile users from WSN to cloud, this paper rst identi es the critical issues that affect the usefulness of sensory data and the reliability of WSN, then proposes a novel WSN-MCC integration scheme named TPSS, which consists of two main parts: 1) time and priority-based selective data transmission (TPSDT) for WSN gateway to selectively transmit sensory data that are more useful to the cloud, considering the time and priority features of the data requested by the mobile user and 2) priority-based sleep scheduling (PSS) algorithm for WSN to save energy consumption so that it can gather and transmit data in a more reliable way. Analytical and experimental results demonstrate the effectiveness of TPSS in improving usefulness of sensory data and reliability of WSN for WSN-MCC integration.

On Traffic-Aware Partition and Aggregation in MapReduce for Big Data Applications
IEEE 2015 TRANSACTIONS ON COMPUTERS
Abstract : The MapReduce programming model simplifies large-scale data processing on commodity cluster by exploiting parallel map tasks and reduce tasks. Although many efforts have been made to improve the performance of MapReduce jobs, they ignore the network traffic generated in the shuffle phase, which plays a critical role in performance enhancement. Traditionally, a hash function is used to partition intermediate data among reduce tasks, which, however, is not traffic-efficient because network topology and data size associated with each key are not taken into consideration. In this paper, we study to reduce network traffic cost for a MapReduce job by designing a novel intermediate data partition scheme. Furthermore, we jointly consider the aggregator placement problem, where each aggregator can reduce merged traffic from multiple map tasks. A decomposition-based distributed algorithm is proposed to deal with the large-scale optimization problem for big data application and an online algorithm is also designed to adjust data partition and aggregation in a dynamic manner. Finally, extensive simulation results demonstrate that our proposals can significantly reduce network traffic cost under both offline and online cases.

IEEE 2015 : A Tree Regression Based Approach for VM Power Metering
IEEE 2015 TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS
Abstract : Cloud computing is developing so fast that more and more data centers have been built every year. This naturally leads to high power consumption. VM (Virtual Machine) consolidation is the most popular solution based on resource utilization. In fact, much more power can be saved if we know the power consumption of each VM. Therefore, it is significant to measure the power consumption of each VM for green cloud data centers. Since there is no device that can directly measure the power consumption of each VM, modeling methods have been proposed. However, current models are not accurate enough when multi-VMs are competing for resources on the same server. One of the main reasons is that the resource features for modeling are correlated with each other, such as CPU and cache. In this paper, we propose a tree regression based method to accurately measure the power consumption of VMs on the same host. The merits of this method are that the tree structure will split the dataset into partitions, and each is an easy-modeling subset. Experiments show that the average accuracy of our method is about 98% for different types of applications running in VMs.

IEEE 2015 : Cost-Minimizing Dynamic Migration of Content Distribution Services into Hybrid Clouds IEEE 2015 TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS
Abstract : The recent advent of cloud computing technologies has enabled agile and scalable resource access for a variety of applications. Content distribution services are a major category of popular Internet applications. A growing number of content providers are contemplating a switch to cloud-based services, for better scalability and lower cost. Two key tasks are involved for such a move: to migrate their contents to cloud storage, and to distribute their web service load to cloud-based web services. The main challenge is to make the best use of the cloud as well as their existing on-premise server infrastructure, to serve volatile content requests with service response time guarantee at all times, while incurring the minimum operational cost. Employing Lyapunov optimization techniques, we present an optimization framework for dynamic, cost-minimizing migration of content distribution services into a hybrid cloud infrastructure that spans geographically distributed data centers. A dynamic control algorithm is designed, which optimally places contents and dispatches requests in different data centers to minimize overall operational cost over time, subject to service response time constraints. Rigorous analysis shows that the algorithm nicely bounds the response times within the preset QoS target in cases of arbitrary request arrival patterns, and guarantees that the overall cost is within a small constant gap from the optimum achieved by a T-slot look ahead mechanism with known information into the future.

IEEE 2015 :A Combinatorial Auction-Based Collaborative Cloud Services Platform
IEEE 2015 TRANSACTIONS ON COMPUTERS
Abstract: In this paper,
we introduce a combinatorial auction-based market model to enable
Cloud Service Providers (CSPs) to satisfy complex user requirements
collaboratively, where the CSPs are connected in a
social network and communication costs among them cannot be ignored.
However, in many situations CSPs may lie about their private information
in order to maximize their earnings. Therefore, we combine the combinatorial
auction with the VCG-auction mechanism to ensure that CSPs do not lie in
auction. Based on above market model, we construct a collaborative cloud
platform, which is divided into three layers: The user-layer receives requests
from end-users, the auction-layer matches the requests with the cloud
services provided by the Cloud Service Provider (CSP), and the CSP-layer
forms a coalition to improve serving ability to satisfy complex requirements of
users. In fact, the aim of the coalition formation is to find suitable
partners for a particular CSP, and, we propose two heuristic
algorithms for the coalition formation. The Breadth Traversal Algorithm
(BTA) and Revised Ant Colony Algorithm (RACA) are proposed to form a
coalition when bidding for a single cloud service in the auction. The
experimental results show that RACA outperforms the BTA in bid price and
our methods work well compared to the existing auction-based method in terms of
economic efficiency. Other experiments were conducted to evaluate the impact of
the communication cost on coalition formation and to assess the impact of
iteration times for the optimal bidding price.

IEEE 2015 : Secure Optimization Computation Outsourcing in Cloud Computing: A Case Study of Linear Programming
IEEE 2015 TRANSACTIONS ON COMPUTERS
Abstract : Cloud computing enables an economically promising paradigm of computation outsourcing. However, how to protect customers confidential data processed and generated during the computation is becoming the major security concern. Focusing on engineering computing and optimization tasks, this paper investigates secure outsourcing of widely applicable linear programming (LP) computations. Our mechanism design explicitly decomposes LP computation outsourcing into public LP solvers running on the cloud and private LP parameters owned by the customer. The resulting flexibility allows us to explore appropriate security/efficiency trade off via higher-level abstraction of LP computation than the general circuit representation. Specifically, by formulating private LP problem as a set of matrices/vectors, we develop efficient privacy-preserving problem transformation techniques, which allow customers to transform the original LP into some random one while protecting sensitive input/output information. To validate the computation result, we further explore the fundamental duality theorem of LP and derive the necessary and sufficient conditions that correct results must satisfy. Such result verification mechanism is very efficient and incurs close-to-zero additional cost on both cloud server and customers. Extensive security analysis and experiment results show the immediate practicability of our mechanism design.

IEEE 2015 : Provable Multi copy Dynamic Data Possession in Cloud Computing System
IEEE 2015 TRANSACTIONS ON INFORMATION FORENSICS AND SECURITY
Abstract : Increasingly more and more organizations are opting for outsourcing data to remote cloud service provi-ders (CSPs). Customers can rent the CSPs storage infrastructure to store and retrieve almost unlimited amount of data by paying fees metered in gigabyte/month. For an increased level of scalability, availability, and durability, some customers may want their data to be replicated on multiple servers across multiple data centers. The more copies the CSP is asked to store, the more fees the customers are charged. Therefore, customers need to have a strong guarantee that the CSP is storing all data copies that are agreed upon in the service contract, and all these copies are consistent with the most recent modifications issued by the customers. In this paper, we propose a map-based provable mul-ticopy dynamic data possession (MB-PMDDP) scheme that has the following features: 1) it provides an evidence to the customers that the CSP is not cheating by storing fewer copies; 2) it supports outsourcing of dynamic data, i.e., it supports block-level opera-tions, such as block modification, insertion, deletion, and append; and 3) it allows authorized users to seamlessly access the file copies stored by the CSP. We give a comparative analysis of the proposed MB-PMDDP scheme with a reference model obtained by extending existing provable possession of dynamic single-copy schemes. The theoretical analysis is validated through experimental results on a commercial cloud platform. In addition, we show the security against colluding servers, and discuss how to identify corrupted copies by slightly modifying the proposed scheme.

IEEE 2015 TRANSACTIONS ON COMPUTERS
Abstract : The capability of selectively sharing encrypted data with different users via public cloud storage may greatly ease security concerns over inadvertent data leaks in the cloud. A key challenge to designing such encryption schemes lies in the efficient management of encryption keys. The desired flexibility of sharing any group of selected documents with any group of users demands different encryption keys to be used for different documents. However, this also implies the necessity of securely distributing to users a large number of keys for both encryption and search, and those users will have to securely store the received keys, and submit an equally large number of keyword trapdoors to the cloud in order to perform search over the shared data. The implied need for secure communication, storage, and complexity clearly renders the approach impractical. In this paper, we address this practical problem, which is largely neglected in the literature, by proposing the novel concept of key-aggregate searchable encryption (KASE) and instantiating the concept through a concrete KASE scheme, in which a data owner only needs to distribute a single key to a user for sharing a large number of documents, and the user only needs to submit a single trapdoor to the cloud for querying the shared documents. The security analysis and performance evaluation both confirm that our proposed schemes are provably secure and practically efficient.
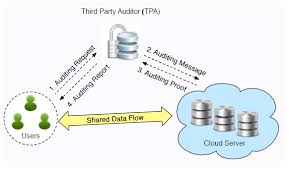
IEEE 2015 TRANSACTIONS ON COMPUTERS
Abstract : The advent of the cloud computing makes storage out-sourcing become a rising trend, which promotes the secure remote data auditing a hot topic that appeared in the research literature. Recently some research consider the problem of secure and efficient public data integrity auditing for shared dynamic data. However, these schemes are still not secure against the collusion of cloud storage server and revoked group users during user revocation in practical cloud storage system. In this paper, we figure out the collusion attack in the exiting scheme and provide an efficient public integrity auditing scheme with secure group user revocation based on vector commitment and verifier-local revocation group signature. We design a concrete scheme based on the our scheme definition. Our scheme supports the public checking and efficient user revoca-tion and also some nice properties, such as confidently, efficiency, countability and traceability of secure group user revocation. Finally, the security and experimental analysis show that, compared with its relevant schemes our scheme is also secure and efficient.

IEEE 2015 :Energy-aware Load Balancing and Application Scaling for the Cloud Ecosystem
IEEE 2015 TRANSACTIONS ON CLOUD COMPUTING
Abstract : In this paper we introduce an energy-aware operation model used for load balancing and application scaling on a cloud. The basic philosophy of our approach is de ning an energy-optimal operation regime and attempting to maximize the number of servers operating in this regime. Idle and lightly-loaded servers are switched to one of the sleep states to save energy. The load balancing and scaling algorithms also exploit some of the most desirable features of server consolidation mechanisms discussed in the literature.

IEEE 2015 : Shared Authority Based Privacy-preserving
Authentication Protocol in Cloud Computing
IEEE 2015 TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS
Abstract: Cloud computing is emerging as a prevalent data interactive paradigm to realize users’ data remotely stored in an online cloud server. Cloud services provide great conveniences for the users to enjoy the on-demand cloud applications without considering the local infrastructure limitations. During the data accessing, different users may be in a collaborative relationship, and thus data sharing becomes significant to achieve productive benefits. The existing security solutions mainly focus on the authentication to realize that a user’s privative data cannot be unauthorized accessed, but neglect a subtle privacy issue during a user challenging the cloud server to request other users for data sharing. The challenged access request itself may reveal the user’s privacy no matter whether or not it can obtain the data access permissions. In this paper, we propose a shared authority based privacy-preserving authentication protocol (SAPA) to address above privacy issue for cloud storage. In the SAPA, 1) shared access authority is achieved by anonymous access request matching mechanism with security and privacy considerations (e.g., authentication, data anonymity, user privacy, and forward security); 2) attribute based access control is adopted to realize that the user can only access its own data fields; 3) proxy re -encryption is applied by the cloud server to provide data sharing among the multiple users. Meanwhile, universal compos ability (UC) model is established to prove that the SAPA theoretically ha s the design correctness. It indicates that the proposed protocol realizing privacy-preserving data access authority sharing, is attractive for multi-user collaborative cloud applications.

IEEE 2015 : I-sieve - An Inline High
Performance Deduplication System Used in Cloud
Storage
IEEE 2015 TRANSACTIONS ON SERVICE
COMPUTING
Abstract :Data
deduplication is an emerging and widely employed method for current storage
systems. As this technology is gradually applied in inline scenarios such as
with virtual machines and cloud storage systems, this study proposes a novel
deduplication architecture called I-sieve. The goal of I-sieve is to
realize a high performance data sieve system based on iSCSI in the cloud
storage system. We also design the corresponding index and mapping tables and
present a multi-level cache using a solid state drive to reduce RAM consumption
and to optimize lookup performance. A prototype of I-sieve is implemented
based on the open source iSCSI target, and many experiments have been conducted
driven by virtual machine images and testing tools. The evaluation results show
excellent deduplication and foreground performance.More importantly, I-sieve
can co-exist with the existing deduplication systems as long as they support
the iSCSI protocol.

IEEE 2015 : Secure and Practical
Outsourcing of Linear Programming
in Cloud Computing
IEEE 2015 TRANSACTIONS ON SERVICE
COMPUTING
Abstract :Cloud
Computing has great potential of providing robust computational power to the
society at reduced cost. It enables customers with limited computational
resources to outsource their large computation workloads to the cloud, and
economically enjoy the massive computational power, bandwidth, storage, and
even appropriate software that can be shared in a pay-per-use manner. Despite
the tremendous benefits, security is the primary obstacle that prevents
the wide adoption of this promising computing model, especially for customers
when their confidential data are consumed and produced during the computation.
Treating the cloud as an intrinsically insecure computing platform from
the viewpoint of the cloud customers, we must design mechanisms that not
only protect sensitive information by enabling computations with encrypted
data, but also protect customers from malicious behaviors by enabling the
validation of the computation result. Such a mechanism of general secure
computation outsourcing was recently shown to be feasible in theory, but
to design mechanisms that are practically efficient remains a very
challenging problem. Focusing on engineering computing and optimization
tasks, this paper investigates secure outsourcing of widely applicable linear
programming (LP) computations. In order to achieve practical efficiency,
our mechanism design explicitly decomposes the LP computation outsourcing
into public LP solvers running on the cloud and private LP parameters
owned by the customer. The resulting flexibility allows us to explore
appropriate security/ efficiency trade off via higher-level abstraction of
LP computations than the general circuit representation. In particular,
by formulating private data owned by the customer for LP problem as a
set of matrices and vectors, we are able to develop a set of efficient
privacy-preserving problem transformation techniques, which allow
customers to transform original LP problem into some arbitrary one while
protecting sensitive input/output information. To validate the computation
result, we further explore the fundamental duality theorem of LP
computation and derive the necessary and sufficient conditions that
correct result must satisfy. Such result verification mechanism is
extremely efficient and incurs close-to-zero additional cost on both cloud
server and customers. Extensive security analysis and experiment results show
the immediate practicability of our mechanism design.

IEEE 2015 : A Profit Maximization Scheme with Guaranteed Quality of
Service in Cloud Computing
IEEE 2015 TRANSACTIONS ON SERVICE COMPUTING
Abstract : As
an effective and efficient way to provide computing resources and services to
customers on demand, cloud computing has become more and more popular. From
cloud service providers’ perspective, profit is one of the most important
considerations, and it is mainly determined by the configuration of a cloud
service platform under given market demand. However, a single long-term renting
scheme is usually adopted to configure a cloud platform, which cannot guarantee
the service quality but leads to serious resource waste. In this paper, a
double resource renting scheme is designed firstly in which short-term renting
and long-term renting are combined aiming at the existing issues. This double
renting scheme can effectively guarantee the quality of service of all requests
and reduce the resource waste greatly. Secondly, a service system is considered
as an M/M/m+D queuing model and the performance indicators that affect
the profit of our double renting scheme are analyzed, e.g., the average charge,
the ratio of requests that need temporary servers, and so forth. Thirdly, a
profit maximization problem is formulated for the double renting scheme and the
optimized configuration of a cloud platform is obtained proposed scheme with
that of the single renting scheme. The results show that our scheme can not
only guarantee the service quality of all requests, but also obtain more profit
than the latter. by solving the profit maximization problem. Finally, a series
of calculations are conducted to compare the profit of our proposed scheme with
that of the single renting scheme.

IEEE 2015 :Key-Aggregate Searchable
Encryption (KASE) for Group Data Sharing via Cloud Storage
IEEE 2015 TRANSACTIONS ON SERVICE COMPUTING
Abstract : The capability of selectively sharing encrypted data with
different users via public cloud storage may greatly ease security concerns
over inadvertent data leaks in the cloud. A key challenge to designing such
encryption schemes lies in the efficient management of encryption keys. The
desired flexibility of sharing any group of selected documents with any group
of users demands different encryption keys to be used for different documents.
However, this also implies the necessity of securely distributing to users a
large number of keys for both encryption and search, and those users will have
to securely store the received keys, and submit an equally large number of
keyword trapdoors to the cloud in order to perform search over the shared data.
The implied need for secure communication, storage, and complexity clearly
renders the approach impractical. In this paper, we address this practical
problem, which is largely neglected in the literature, by proposing the novel
concept of key aggregate searchable encryption (KASE) and instantiating
the concept through a concrete KASE scheme, in which a data owner only needs to
distribute a single key to a user for sharing a large number of documents, and
the user only needs to submit a single trapdoor to the cloud for querying the
shared documents. The security analysis and performance evaluation both confirm that our proposed schemes are provably secure and practice ally efficient.

IEEE 2015 : Secure Auditing and Deduplicating Data in Cloud
IEEE 2015 TRANSACTIONS ON SERVICE COMPUTING
IEEE 2015 TRANSACTIONS ON SERVICE COMPUTING
Abstract :As
the cloud computing technology develops during the last decade, outsourcing
data to cloud service for storage becomes an attractive trend, which benefits
in sparing efforts on heavy data maintenance and management. Nevertheless,
since the outsourced cloud storage is not fully trustworthy, it raises security
concerns on how to realize data deduplication in cloud while achieving integrity
auditing. In this work, we study the problem of integrity auditing and secure
deduplication on cloud data. Specifically, aiming at achieving both data
integrity and deduplication in cloud, we propose two secure systems, namely
SecCloud and SecCloud+. SecCloud introduces an auditing entity with a
maintenance of a MapReduce cloud, which helps clients generate data tags before
uploading as well as audit the integrity of data having been stored in cloud.
Compared with previous work, the computation by user in SecCloud is greatly
reduced during the file uploading and auditing phases. SecCloud+ is designed
motivated by the fact that customers always want to encrypt their data before
uploading, and enables integrity auditing and secure deduplication on encrypted
data.

IEEE 2014 : Fog
Computing: Mitigating Insider Data Theft Attacks in the Cloud
IEEE 2014 TRANSACTIONS ON SERVICE COMPUTING
Abstract :Cloud computing promises to significantly change the way we use computers
and access and store our personal and business information. With these new
computing and communications paradigms arise new data security challenges. Existing
data protection mechanisms such as encryption have failed in preventing data
theft attacks, especially those perpetrated by an insider to the cloud
provider. We propose a different approach for securing data in the cloud using
offensive decoy technology. We monitor data access in the cloud and detect
abnormal data access patterns. When unauthorized access is suspected and then
verified using challenge questions, we launch a disinformation attack by
returning large amounts of decoy information to the attacker. This protects
against the misuse of the user’s real data. Experiments conducted in a local
file setting provide evidence that this approach may provide unprecedented
levels of user data security in a Cloud environment.

IEEE 2014 :Se Das: A Self-Destructing
Data System Based on Active Storage Framework
IEEE 2014 TRANSACTIONS ON SERVICE COMPUTING
Abstract :Personal data stored in the Cloud may contain
account numbers, passwords, notes, and other important information that could
be used and misused by a miscreant, a competitor, or a court of law. These data
are cached, copied, and archived by Cloud Service Providers (CSPs), often
without users’ authorization and control. Self-destructing data mainly aims at
protecting the user data’s privacy. All the data and their copies become
destructed or unreadable after a user-specified time, without any user
intervention. In addition, the decryption key is destructed after the
user-specified time. In this paper, we present Se Das, a system that meets this
challenge through a novel integration of cryptographic techniques with active
storage techniques based on T10 OSD standard. We implemented a proof-of-concept
Se Das prototype. Through functionality and security properties evaluations of
the Se Das prototype, the results demonstrate that Se Das is practical to use
and meets all the privacy-preserving goals described. Compared to the system
without self-destructing data mechanism, throughput for uploading and
downloading with the proposed Se Das acceptably decreases by less than 72%,
while latency for upload/download operations with self-destructing data
mechanism increases by less than 60%.

IEEE 2014 :AMES-Cloud: A
Framework of Adaptive Mobile Video Streaming and Efficient Social Video Sharing
in the Clouds
IEEE 2014 TRANSACTIONS ON SERVICE
COMPUTING
Abstract :While
demands on video traffic over mobile networks have been souring, the wireless
link capacity cannot keep up with the traffic demand. The gap between the
traffic demand and the link capacity, along with time-varying link conditions,
results in poor service quality of video streaming over mobile networks such as
long buffering time and intermittent disruptions. Leveraging the cloud
computing technology, we propose a new mobile video streaming framework, dubbed
AMES-Cloud, which has two main parts: adaptive mobile video streaming (AMoV)
and efficient social video sharing (ESoV). A MoV and ESoV construct a private
agent to provide video streaming services efficiently for each mobile user. For
a given user, A MoV lets her private agent adaptively adjust her streaming flow
with a scalable video coding technique based on the feedback of link quality.
Likewise, ESo V monitors the social network interactions among mobile users,
and their private agents try to prefetch video content in advance. We implement
a prototype of the AMES-Cloud framework to demonstrate its performance. It is
shown that the private agents in the clouds can effectively provide the
adaptive streaming, and perform video sharing (i.e., prefetching) based on the
social network analysis.

IEEE 2014 : Cloud-Assisted
Mobile-Access of Health Data With Privacy and Auditability
IEEE
JOURNAL OF BIOMEDICAL AND HEALTH INFORMATICS
Abstract :Motivated by
the privacy issues, curbing the adoption of electronic healthcare systems and
the wild success of cloud service models, we propose to build privacy into
mobile healthcare systems with the help of the private cloud. Our system offers
salient features including efficient key management, privacy-preserving data
storage, and retrieval, especially for retrieval at emergencies, and audit
ability for misusing health data. Specifically, we propose to integrate key
management from pseudorandom number generator for unlink ability, a secure
indexing method for privacy preserving keyword search which hides both search
and access patterns based on redundancy, and integrate the concept of attribute
based encryption with threshold signing for providing role-based access control
with audit ability to prevent potential misbehavior, in both normal and
emergency cases.

IEEE 2014 : VABKS - Verifiable Attribute-based Keyword Search over Outsourced Encrypted Data
Abstract :It is common nowadays for
data owners to outsource their data to the cloud. Since the cloud cannot be
fully trusted, the outsourced data should be encrypted. This however brings a
range of problems, such as: How should a data owner grant search capabilities
to the data users? How can the authorized data users search over a data owner’s
outsourced encrypted data? How can the data users be assured that the cloud
faithfully executed the search operations on their behalf? Motivated by these
questions, we propose a novel cryptographic solution, called verifiable
attribute-based keyword search (VABKS). The solution allows a data user, whose
credentials satisfy a data owner’s access control policy, to (i) search over
the data owner’s outsourced encrypted data, (ii) outsource the tedious search
operations to the cloud, and (iii) verify whether the cloud has faithfully
executed the search operations. We formally define the security requirements of
VABKS and describe a construction that satisfies them. Performance evaluation
shows that the proposed schemes are practical and deployable.

IEEE 2014 : Securing Broker-Less
Publish/Subscribe Systems Using
Identity-Based Encryption
IEEE 2014
TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS
Abstract :The
provisioning of basic security mechanisms such as authentication and
confidentiality is highly challenging in a content based publish/subscribe
system. Authentication of publishers and subscribers is difficult to achieve
due to the loose coupling of publishers and subscribers. Likewise,
confidentiality of events and subscriptions conflicts with content-based
routing. This paper presents a novel approach to provide confidentiality and
authentication in a broker-less content-based publish/subscribe system. The
authentication of publishers and subscribers as well as confidentiality of
events is ensured, by adapting the pairing-based cryptography mechanisms, to
the needs of a publish/subscribe system. Furthermore, an algorithm to cluster
subscribers according to their subscriptions preserves a weak notion of
subscription confidentiality. In addition to our previous work, this paper
contributes 1) use of searchable encryption to enable efficient routing of
encrypted events, 2) multicredential routing a new event dissemination strategy
to strengthen the weak subscription confidentiality, and 3) thorough analysis
of different attacks on subscription confidentiality. The overall approach
provides fine-grained key management and the cost for encryption, decryption,
and routing is in the order of subscribed attributes. Moreover, the evaluations
show that providing security is affordable w.r.t. 1) throughput of the proposed
cryptographic primitives, and 2) delays incurred during the construction of the
publish/subscribe overlay and the event dissemination. Security requirements of
VABKS and describe a construction that satisfies them. Performance evaluation
shows that the proposed schemes are practical and deployable.

IEEE 2014: 6th International Conference on New Technologies, Mobility and Security (NTMS)
Abstract :Recent years have witnessed the trend of leveraging cloud-based services for large scale content storage, processing, and distribution. Security and privacy are among top concerns for the public cloud environments. Towards these security challenges, we propose and implement, on Open Stack Swift, a new client-side deduplication scheme for securely storing and sharing outsourced data via the public cloud. The originality of our proposal is twofold. First, it ensures better confidentiality towards unauthorized users. That is, every client computes a per data key to encrypt the data that he intends to store in the cloud. As such, the data access is managed by the data owner. Second, by integrating access rights in metadata file, an authorized user can decipher an encrypted file only with his private key.
Abstract :Recent years have witnessed the trend of leveraging cloud-based services for large scale content storage, processing, and distribution. Security and privacy are among top concerns for the public cloud environments. Towards these security challenges, we propose and implement, on Open Stack Swift, a new client-side deduplication scheme for securely storing and sharing outsourced data via the public cloud. The originality of our proposal is twofold. First, it ensures better confidentiality towards unauthorized users. That is, every client computes a per data key to encrypt the data that he intends to store in the cloud. As such, the data access is managed by the data owner. Second, by integrating access rights in metadata file, an authorized user can decipher an encrypted file only with his private key.

IEEE 2014 : Attribute Based Encryption with Privacy Preserving In Clouds
IEEE 2014 TRANSACTIONS ON KNOWLEDGE & DATA ENGINEERING
IEEE 2014 TRANSACTIONS ON KNOWLEDGE & DATA ENGINEERING
Abstract : Security and privacy are very important issues in cloud computing. In existing system access control in clouds are centralized in nature. The scheme uses a symmetric key approach and does not support authentication. Symmetric key algorithm uses same key for both encryption and decryption. The authors take a centralized approach where a single key distribution center (KDC) distributes secret keys and attributes to all users. A new decentralized access control scheme for secure data storage in clouds that supports anonymous authentication. The validity of the user who stores the data is also verified. The proposed scheme is resilient to replay attacks. In this scheme using Secure Hash algorithm for authentication purpose, SHA is the one of several cryptographic hash functions, most often used to verify that a file has been unaltered. The Paillier crypto system is a probabilistic asymmetric algorithm for public key cryptography. Pailier algorithm use for Creation of access policy, file accessing and file restoring process.

IEEE 2014 Transactions on Cloud Computing
Abstract : With cloud data services, it is commonplace for data to be not only stored in the cloud, but also shared across multiple users. Unfortunately, the integrity of cloud data is subject to skepticism due to the existence of hardware/software failures and human errors. Several mechanisms have been designed to allow both data owners and public verifiers to efficiently audit cloud data integrity without retrieving the entire data from the cloud server. However, public auditing on the integrity of shared data with these existing mechanisms will inevitably reveal confidential information-identity privacy-to public verifiers. In this paper, we propose a novel privacy-preserving mechanism that supports public auditing on shared data stored in the cloud. In particular, we exploit ring signatures to compute verification metadata needed to audit the correctness of shared data. With our mechanism, the identity of the signer on each block in shared data is kept private from public verifiers, who are able to efficiently verify shared data integrity without retrieving the entire file. In addition, our mechanism is able to perform multiple auditing tasks simultaneously instead of verifying them one by one. Our experimental results demonstrate the effectiveness and efficiency of our mechanism

IEEE 2014 Transactions on Cloud Computing
Abstract :Cloud computing
is emerging as a prevalent data interactive paradigm to realize users’ data
remotely stored in an online cloud server. Cloud services provide great
conveniences for the users to enjoy the on-demand cloud applications without
considering the local infrastructure limitations. During the data accessing,
different users may be in a collaborative relationship, and thus data sharing
becomes significant to achieve productive benefits. The existing security
solutions mainly focus on the authentication to realize that a user’s privative
data cannot be unauthorized accessed, but neglect a subtle privacy issue during
a user challenging the cloud server to request other users for data sharing.
The challenged access request itself may reveal the user’s privacy no matter
whether or not it can obtain the data access permissions. In this paper, we
propose a shared authority based privacy-preserving authentication protocol
(SAPA) to address above privacy issue for cloud storage. In the SAPA, 1) shared
access authority is achieved by anonymous access request matching mechanism
with security and privacy considerations (e.g., authentication, data anonymity,
user privacy, and forward security); 2) attribute based access control is
adopted to realize that the user can only access its own data fields; 3) proxy
re-encryption is applied by the cloud server to provide data sharing among the
multiple users. Meanwhile, universal composability (UC) model is established
to prove that the SAPA theoretically has the design correctness. It indicates
that the proposed protocol realizing privacy-preserving data access authority
sharing, is attractive for multi-user collaborative cloud applications. 
IEEE 2014 Transactions on Cloud Computing
Abstract :This paper presents a novel economic model to regulate capacity sharing in a federation of hybrid cloud providers (CPs). The proposed work models the interactions among the CPs as a repeated game among selfish players that aim at maximizing their profit by selling their unused capacity in the spot market but are uncertain of future workload fluctuations. The proposed work first establishes that the uncertainty in future revenue can act as a participation incentive to sharing in the repeated game. We, then, demonstrate how an efficient sharing strategy can be obtained via solving a simple dynamic programming problem. The obtained strategy is a simple update rule that depends only on the current workloads and a single variable summarizing past interactions. In contrast to existing approaches, the model incorporates historical and expected future revenue as part of the virtual machine (VM) sharing decision. Moreover, these decisions are not enforced neither by a centralized broker nor by predefined agreements. Rather, the proposed model employs a simple grim trigger strategy where a CP is threatened by the elimination of future VM hosting by other CPs. Simulation results demonstrate the performance of the proposed model in terms of the increased profit and the reduction in the variance in the spot market VM availability and prices.

IEEE 2014 : Proactive Workload Management in Hybrid Cloud Computing
IEEE 2014 Transactions on Cloud Computing
Abstract :The hindrances to the adoption of public cloud computing services include service reliability, data security and privacy, regulation compliant requirements, and so on. To address those concerns, we propose a hybrid cloud computing model which users may adopt as a viable and cost-saving methodology to make the best use of public cloud services along with their privately-owned (legacy) data centers. As the core of this hybrid cloud computing model, an intelligent workload factoring service is designed for proactive workload management. It enables federation between on- and off-premise infrastructures for hosting Internet-based applications, and the intelligence lies in the explicit segregation of base workload and flash crowd workload, the two naturally different components composing the application workload. The core technology of the intelligent workload factoring service is a fast frequent data item detection algorithm, which enables factoring incoming requests not only on volume but also on data content, upon a changing application data popularity. Through analysis and extensive evaluation with real-trace driven simulations and experiments on a hybrid testbed consisting of local computing platform and Amazon Cloud service platform, we showed that the proactive workload management technology can enable reliable workload prediction in the base workload zone (with simple statistical methods), achieve resource efficiency (e.g., 78% higher server capacity than that in base workload zone) and reduce data cache/replication overhead (up to two orders of magnitude) in the flash crowd workload zone, and react fast (with an X2 speed-up factor) to the changing application data popularity upon the arrival of load spikes.

IEEE 2014 Transactions on Cloud Computing
Abstract :Facing massive multimedia services and contents in the Internet, mobile users usually waste a lot of time to obtain their interests. Therefore, various context-aware recommendations systems have been proposed. Most of those proposed systems deploy a large number of context collectors at terminals and access networks. However, the context collecting and exchanging result in heavy network overhead, and the context processing consumes huge computation. In this paper, a cloud-based mobile multimedia recommendation system which can reduce network overhead and speed up the recommendation process is proposed. The users are classified into several groups according to their context types and values. With the accurate classification rules, the context details are not necessary to compute, and the huge network overhead is reduced. Moreover, user contexts, user relationships, and user profiles are collected from video-sharing websites to generate multimedia recommendation rules based on the Hadoop platform. When a new user request arrives, the rules will be extended and optimized to make real-time recommendation. The results show that the proposed approach can recommend desired services with high precision, high recall, and low response delay.

IEEE 2014 Transactions on Cloud Computing
Abstract :With the advent of cloud computing, data owners are motivated to outsource their complex data management systems from local sites to the commercial public cloud for great flexibility and economic savings. But for protecting data privacy, sensitive data have to be encrypted before outsourcing, which obsoletes traditional data utilization based on plaintext keyword search. Thus, enabling an encrypted cloud data search service is of paramount importance. Considering the large number of data users and documents in the cloud, it is necessary to allow multiple keywords in the search request and return documents in the order of their relevance to these keywords. Related works on searchable encryption focus on single keyword search or Boolean keyword search, and rarely sort the search results. In this paper, for the first time, we define and solve the challenging problem of privacy-preserving multi-keyword ranked search over encrypted data in cloud computing (MRSE). We establish a set of strict privacy requirements for such a secure cloud data utilization system. Among various multi-keyword semantics, we choose the efficient similarity measure of “coordinate matching,” i.e., as many matches as possible, to capture the relevance of data documents to the search query. We further use “inner product similarity” to quantitatively evaluate such similarity measure. We first propose a basic idea for the MRSE based on secure inner product computation, and then give two significantly improved MRSE schemes to achieve various stringent privacy requirements in two different threat models. To improve search experience of the data search service, we further extend these two schemes to support more search semantics. Thorough analysis investigating privacy and efficiency guarantees of proposed schemes is given. Experiments on the real-world data set further show proposed schemes indeed introduce low overhead on computation and communication.

IEEE 2014 TRANSACTIONS ON SERVICE COMPUTING

IEEE 2014 TRANSACTIONS ON SERVICE COMPUTING
Abstract :Data deduplication is one of important data compression techniques for eliminating duplicate copies of repeating data, and has been widely used in cloud storage to reduce the amount of storage space and save bandwidth. To protect the confidentiality of sensitive data while supporting deduplication, the convergent encryption technique has been proposed to encrypt the data before outsourcing. To better protect data security, this paper makes the first attempt to formally address the problem of authorized data deduplication. Different from traditional deduplication systems, the differential privileges of users are further considered in duplicate check besides the data itself. We also present several new deduplication constructions supporting authorized duplicate check in a hybrid cloud architecture. Security analysis demonstrates that our scheme is secure in terms of the definitions specified in the proposed security model. As a proof of concept, we implement a prototype of our proposed authorized duplicate check scheme and conduct testbed experiments using our prototype. We show that our proposed authorized duplicate check scheme incurs minimal overhead compared to normal operations.
Abstract :Data deduplication is one of important data compression techniques for eliminating duplicate copies of repeating data, and has been widely used in cloud storage to reduce the amount of storage space and save bandwidth. To protect the confidentiality of sensitive data while supporting deduplication, the convergent encryption technique has been proposed to encrypt the data before outsourcing. To better protect data security, this paper makes the first attempt to formally address the problem of authorized data deduplication. Different from traditional deduplication systems, the differential privileges of users are further considered in duplicate check besides the data itself. We also present several new deduplication constructions supporting authorized duplicate check in a hybrid cloud architecture. Security analysis demonstrates that our scheme is secure in terms of the definitions specified in the proposed security model. As a proof of concept, we implement a prototype of our proposed authorized duplicate check scheme and conduct testbed experiments using our prototype. We show that our proposed authorized duplicate check scheme incurs minimal overhead compared to normal operations.

IEEE 2014 TRANSACTIONS ON SERVICE COMPUTING
Abstract :Cloud computing is emerging as a new computing paradigm in the healthcare sector besides other business domains. Large numbers of health organizations have started shifting the electronic health information to the cloud environment. Introducing the cloud services in the health sector not only facilitates the exchange of electronic medical records among the hospitals and clinics, but also enables the cloud to act as a medical record storage center. Moreover, shifting to the cloud environment relieves the healthcare organizations of the tedious tasks of infrastructure management and also minimizes development and maintenance costs. Nonetheless, storing the patient health data in the third-party servers also entails serious threats to data privacy. Because of probable disclosure of medical records stored and exchanged in the cloud, the patients’ privacy concerns should essentially be considered when designing the security and privacy mechanisms. Various approaches have been used to preserve the privacy of the health information in the cloud environment. This survey aims to encompass the state-of-the-art privacy preserving approaches employed in the e-Health clouds. Moreover, the privacy preserving approaches are classified into cryptographic and non-cryptographic approaches and taxonomy of the approaches is also presented. Furthermore, the strengths and weaknesses of the presented approaches are reported and some open issues are highlighted
ans-serif

IEEE 2014 TRANSACTIONS ON SERVICE COMPUTING
Abstract :By leveraging virtual machine (VM) technology which provides performance and fault isolation, cloud resources can be provisioned on demand in a fine grained, multiplexed manner rather than in monolithic pieces. By integrating volunteer computing into cloud architectures, we envision a gigantic self-organizing cloud (SOC) being formed to reap the huge potential of untapped commodity computing power over the Internet. Toward this new architecture where each participant may autonomously act as both resource consumer and provider, we propose a fully distributed, VM-multiplexing resource allocation scheme to manage decentralized resources. Our approach not only achieves maximized resource utilization using the proportional share model (PSM), but also delivers provably and adaptively optimal execution efficiency. We also design a novel multiattribute range query protocol for locating qualified nodes. Contrary to existing solutions which often generate bulky messages per request, our protocol produces only one lightweight query message per task on the Content Addressable Network (CAN). It works effectively to find for each task its qualified resources under a randomized policy that mitigates the contention among requesters. We show the SOC with our optimized algorithms can make an improvement by 15-60 percent in system throughput than a P2P Grid model. Our solution also exhibits fairly high adaptability in a dynamic node-churning environment.

IEEE 2014 TRANSACTIONS ON SERVICE COMPUTING
Abstract :We propose a new decentralized access control scheme for secure data storage in clouds, that supports anonymous authentication. In the proposed scheme, the cloud verifies the authenticity of the ser without knowing the user’s identity before storing data. Our scheme also has the added feature of access control in which only valid users are able to decrypt the stored information. The scheme prevents replay attacks and supports creation, modification, and reading data stored in the cloud. We also address user revocation. Moreover, our authentication and access control scheme is decentralized and robust, unlike other access control schemes designed for clouds which are centralized. The communication, computation, and storage overheads are comparable to centralized approaches.
Abstract :We propose a new decentralized access control scheme for secure data storage in clouds, that supports anonymous authentication. In the proposed scheme, the cloud verifies the authenticity of the ser without knowing the user’s identity before storing data. Our scheme also has the added feature of access control in which only valid users are able to decrypt the stored information. The scheme prevents replay attacks and supports creation, modification, and reading data stored in the cloud. We also address user revocation. Moreover, our authentication and access control scheme is decentralized and robust, unlike other access control schemes designed for clouds which are centralized. The communication, computation, and storage overheads are comparable to centralized approaches.

IEEE 2014 : An Efficient Information Retrieval Approach for Collaborative Cloud Computing
IEEE 2014 TRANSACTIONS ON SERVICE COMPUTING
Abstract :The collaborative cloud computing (CCC) which is collaboratively supported by various organizations (Google, IBM, AMAZON, MICROSOFT) offers a promising future for information retrieval. Human beings tend to keep things simple by moving the complex aspects to computing. As a consequence, we prefer to go to one or a limited number of sources for all our information needs. In contemporary scenario where information is replicated, modified (value added), and scattered geographically; retrieving information in a suitable form requires lot more effort from the user and thus difficult. For instance, we would like to go directly to the source of information and at the same time not to be burdened with additional effort. This is where, we can make use of learning systems (Neural Network based) that can intelligently decide and retrieve the information that we need by going directly to the source of information. This also, reduces single point of failure and eliminates bottlenecks in the path of information flow, Reduces the Time delay and it provide remarkable ability to overcome from traffic conjection complicated patterns. It makes Efficient information retrieval approach for collaborative cloud computing. both secure and verifiable, without relying on random oracles. Finally, we show an implementation of our
Abstract :The collaborative cloud computing (CCC) which is collaboratively supported by various organizations (Google, IBM, AMAZON, MICROSOFT) offers a promising future for information retrieval. Human beings tend to keep things simple by moving the complex aspects to computing. As a consequence, we prefer to go to one or a limited number of sources for all our information needs. In contemporary scenario where information is replicated, modified (value added), and scattered geographically; retrieving information in a suitable form requires lot more effort from the user and thus difficult. For instance, we would like to go directly to the source of information and at the same time not to be burdened with additional effort. This is where, we can make use of learning systems (Neural Network based) that can intelligently decide and retrieve the information that we need by going directly to the source of information. This also, reduces single point of failure and eliminates bottlenecks in the path of information flow, Reduces the Time delay and it provide remarkable ability to overcome from traffic conjection complicated patterns. It makes Efficient information retrieval approach for collaborative cloud computing. both secure and verifiable, without relying on random oracles. Finally, we show an implementation of our

IEEE 2014 : Adaptive Algorithm for Minimizing Cloud Task Length with Prediction Errors
IEEE 2014 TRANSACTIONS ON SERVICE COMPUTING

IEEE 2014 : Secure Outsourced Attribute-Based Signatures
IEEE 2014 TRANSACTIONS ON SERVICE COMPUTING
Abstract :Attribute-based signature (ABS) is a useful variant of digital signature, which enables users to sign messages over attributes without revealing any information other than the fact that they have attested to the messages. However, heavy computational cost is required during signing in existing work of ABS, which grows linearly with the size of the predicate formula. As a result, this presents a signi_cant challenge for resource-limited users (such as mobile devices) to perform such heavy computation independently. Aiming at tackling the challenge above, we propose and formalize a new paradigm called OABS, in which the computational overhead at user side is greatly reduced through outsourcing such intensive computation to an un trusted signing-cloud service provider (S-CSP). Furthermore, we apply this novel paradigm to existing ABS to reduce complexity and present two schemes, i) in the _rst OABS scheme, the number of exponentiations involving in signing is reduced from O(d) to O(1) (nearly three), where d is the upper bound of threshold value de_ned in the predicate; ii) our second scheme is built on Herranz et al's construction with constant-size signatures. The number of exponentiations in signing is reduced from O(d2) to O(d) and the communication overhead is O(1). Security analysis demonstrates that both OABS schemes are secure in terms of the enforceability and attribute- signer privacy dentitions speci_ed in the proposed security model. Finally, to allow for high e_ciency and exibility, we discuss extensions of OABS and show how to achieve accountability and outsourced veri_cation as well.
IEEE 2014 TRANSACTIONS ON SERVICE COMPUTING
Abstract :Attribute-based signature (ABS) is a useful variant of digital signature, which enables users to sign messages over attributes without revealing any information other than the fact that they have attested to the messages. However, heavy computational cost is required during signing in existing work of ABS, which grows linearly with the size of the predicate formula. As a result, this presents a signi_cant challenge for resource-limited users (such as mobile devices) to perform such heavy computation independently. Aiming at tackling the challenge above, we propose and formalize a new paradigm called OABS, in which the computational overhead at user side is greatly reduced through outsourcing such intensive computation to an un trusted signing-cloud service provider (S-CSP). Furthermore, we apply this novel paradigm to existing ABS to reduce complexity and present two schemes, i) in the _rst OABS scheme, the number of exponentiations involving in signing is reduced from O(d) to O(1) (nearly three), where d is the upper bound of threshold value de_ned in the predicate; ii) our second scheme is built on Herranz et al's construction with constant-size signatures. The number of exponentiations in signing is reduced from O(d2) to O(d) and the communication overhead is O(1). Security analysis demonstrates that both OABS schemes are secure in terms of the enforceability and attribute- signer privacy dentitions speci_ed in the proposed security model. Finally, to allow for high e_ciency and exibility, we discuss extensions of OABS and show how to achieve accountability and outsourced veri_cation as well.

IEEE 2014 TRANSACTIONS ON SERVICE COMPUTING
Abstract :Recent years have witnessed the trend of leveraging cloud-based services for large scale content storage, processing, and distribution. Security and privacy are among top concerns for the public cloud environments. Towards these security challenges, we propose and implement, on Open Stack Swift, a new client-side deduplication scheme for securely storing and sharing outsourced data via the public cloud. The originality of our proposal is twofold. First, it ensures better confidentiality towards unauthorized users. That is, every client computes a per data key to encrypt the data that he intends to store in the cloud. As such, the data access is managed by the data owner. Second, by integrating access rights in metadata file, an authorized user can decipher an encrypted file only with his private key. ed from O(d2) to O(d) and the communication overhead is O(1). Security analysis demonstrates that both OABS schemes are secure in terms of the enforceability and attribute- signer privacy dentitions speci_ed in the proposed security model. Finally, to allow for high e_ciency and exibility, we discuss extensions of OABS and show how to achieve accountability and outsourced veri_cation as well.

IEEE 2014 TRANSACTIONS ON SERVICE COMPUTING
Abstract :With the wide deployment of public cloud computing infrastructures, using clouds to host data query services has become an appealing solution for the advantages on scalability and cost-saving. However, some data might be sensitive that the data owner does not want to move to the cloud unless the data confidentiality and query privacy are guaranteed. On the other hand, a secured query service should still provide efficient query processing and significantly reduce the in-house workload to fully realize the benefits of cloud computing. We propose the RASP data perturbation method to provide secure and efficient range query and kNN query services for protected data in the cloud. The RASP data perturbation method combines order preserving encryption, dimensionality expansion, random noise injection, and random projection, to provide strong resilience to attacks on the perturbed data and queries. It also preserves multidimensional ranges, which allows existing indexing techniques to be applied to speedup range query processing. The kNN-R algorithm is designed to work with the RASP range query algorithm to process the kNN queries. We have carefully analyzed the attacks on data and queries under a precisely defined threat model and realistic security assumptions. Extensive experiments have been conducted to show the advantages of this approach on efficiency and security.

IEEE 2014 Transactions on Cloud Computing

IEEE 2014 : Consistency as a Service: Auditing Cloud Consistency
IEEE 2014 Transactions on Network and Service Management
Abstract :Cloud storage services have become commercially
popular due to their overwhelming advantages. To provide ubiquitous always-on
access, a cloud service provider (C S P) maintains multiple replicas for each
piece of data on geographically distributed servers. A key problem of using the
replication technique in clouds is that it is very expensive to achieve strong
consistency on a worldwide scale. In this paper, we first present a novel
consistency as a service (CaaS) model, which consists of a large data cloud and
multiple small audit clouds. In the CaaS model, a data cloud is maintained by a
CSP, and a group of users that constitute an audit cloud can verify whether the
data cloud provides the promised level of consistency or not. We propose a
two-level auditing architecture, which only requires a loosely synchronized
clock in the audit cloud. Then, we design Algorithms to quantify the
severity of violations with two metrics: the commonality of violations, and the
staleness of the value of a read. Finally, we devise a heuristic auditing
strategy (HAS) to reveal as many violations as possible. Extensive experiments
were performed using a combination of simulations and real cloud deployments to
validate HAVE.
which brings a great
comfort to them compared to systems that force users to assig
IEEE 2014 Transactions on Computer
Abstract :The cloud is emerging for scalable and efficient cloud services. To meet the needs of handling massive data and decreasing data migration, the computation infrastructure requires efficient data placement and proper management for cached data. In this paper, we propose an efficient and cost-effective multilevel caching scheme, called MERCURY, as computation infrastructure of the cloud. The idea behind MERCURY is to explore and exploit data similarity and support efficient data placement. To accurately and efficiently capture the data similarity, we leverage a low-complexity locality-sensitive hashing (LSH). In our design, in addition to the problem of space inefficiency, we identify that a conventional LSH scheme also suffers from the problem of homogeneous data placement. To address these two problems, we design a novel multi core-enabled locality-sensitive hashing (MC-LSH) that accurately captures the differentiated similarity across data. The similarity-aware MERCURY, hence, partitions data into the L1 cache, L2 cache, and main memory based on their distinct localities, which help optimize cache utilization and minimize the pollution in the last-level cache. Besides extensive evaluation through simulations, we also implemented MERCURY in a system. Experimental results based.On real-world applications and data sets demonstrate the efficiency and efficacy of our proposed schemes.
rt to them compared to systems that force users to assign exact weights for all preferences.

IEEE 2012 Transactions on Cloud Computing
Abstract :We study the infinite horizon dynamic pricing problem for an infrastructure cloud provider in the emerging cloud computing paradigm. The cloud provider, such as Amazon, provides computing capacity in the form of virtual instances and charges customers a time-varying price for the period they use the instances. The provider’s problem is then to find an optimal pricing policy, in face of stochastic demand arrivals and departures, so that the average expected revenue is maximized in the long run. We adopt a revenue management framework to tackle the problem. Optimality conditions and structural results are obtained for our stochastic formulation, which yield insights on the optimal pricing strategy. Numerical results verify our analysis and reveal additional properties of optimal pricing policies for the Infinite horizon case.
.

IEEE 2014 Transactions on Parallel and Distributed Systems
Abstract :To protect outsourced data in cloud storage against corruptions, enabling integrity protection, fault tolerance, and efficient recovery for cloud storage becomes critical. Regenerating codes provide fault tolerance by striping data across multiple servers, while using less repair traffic than traditional erasure codes during failure recovery. Therefore, we study the problem of remotely checking the integrity of regenerating-coded data against corruptions under a real-life cloud storage setting. We Design and implement a practical data integrity protection (DIP) scheme for a specific regenerating code, while preserving the intrinsic properties of fault tolerance and repair traffic saving. Our DIP scheme is designed under a Byzantine adversarial model, and enables a client to feasibly verify the integrity of random subsets of outsourced data against general or malicious corruptions. It works under the simple assumption of thin-cloud storage and allows different parameters to be fine-tuned for the performance-security trade-off. We implement and evaluate the overhead of our DIP scheme in a real cloud storage test bed under different parameter choices. We demonstrate that remote integrity checking can be feasibly integrated into regenerating codes in practical deployment and minimize the pollution in the last-level cache. Besides extensive evaluation through simulations, we also implemented MERCURY in a system. Experimental results based.On real-world applications and data sets demonstrate the efficiency and efficacy of our proposed schemes to them compared to systems that force users to assign exact weights for all preferences.

IEEE 2014 :Transactions on Parallel and Distributed Systems
Abstract :Data sharing is an important functionality in cloud storage. In this article, we show how to securely, efficiently, and flexibly share data with others in cloud storage. We describe new public-key cryptosystems which produce constant-size cipher texts such that efficient delegation of decryption rights for any set of cipher texts are possible. The novelty is that one can aggregate any set of secret keys and make them as compact as a single key, but encompassing the power of all the keys being aggregated. In other words, the secret key holder can release a constant-size aggregate key for flexible choices of cipher text set in cloud storage, but the other encrypted files outside the set remain confidential. This compact aggregate key can be conveniently sent to others or be stored in a smart card with very limited secure storage. We provide formal security analysis of our schemes in the standard model. We also describe other application of our schemes. In particular, our schemes give the first public-key patient-controlled encryption for flexible hierarchy, which was yet to be known.

IEEE 2014 Journal on Selected Areas in Communications
Abstract :Energy consumption in telecommunication networks
keeps growing rapidly, mainly due to emergence of new Cloud Computing (CC)
services that need to be supported by large data centers that consume a huge
amount of energy and, in turn, cause the emission of enormous quantity of CO2.
Given the decreasing availability of fossil fuels and the raising concern about
global warming, research is now focusing on novel “low-carbon” telecom
solutions. E.g., based on today telecom technologies, data centers can be
located near renewable energy plants and data can then be effectively
transferred to these locations via reconfigurable optical networks, based on
the principle that data can be moved more efficiently than electricity. This
paper focuses on how to dynamically route on-demand optical circuits that are
established to transfer energy-intensive data processing towards data centers
powered with renewable energy. Our main contribution consists in devising two
routing algorithms for connections supporting CC services, aimed at minimizing
the CO2 emissions of data centers by following the current availability of
renewable energy (Sun and Wind). The trade-off with energy consumption for the
transport equipments is also considered. The results show that relevant
reductions, up to about 30% in CO2 emissions can be achieved using our
approaches compared to baseline shortest path- based routing strategies, paying
off only a marginal increase in terms of network blocking probability.
IEEE 2014 TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS
Abstract : Storage outsourcing in cloud computing is a rising trend which
prompts a number of interesting security issues. Provable data possession (PDP)
is a method for ensuring the integrity of data in storage outsourcing. This
research addresses the construction of efficient PDP which called as
Cooperative PDP (CPDP) mechanism for distributed cloud storage to support data
migration and scalability of service, which considers the existence of multiple
cloud service providers to collaboratively store and maintain the clients’
data. Cooperative PDP (CPDP) mechanism is based on homomorphic verifiable
response, hash index hierarchy for dynamic scalability, cryptographic encryption
for security. Moreover, it proves the security of scheme based on multi-prover
zero knowledge proof system, which can satisfy knowledge soundness,
completeness, and zero-knowledge properties. This research introduces lower
computation and communication overheads in comparison with non-cooperative
approaches.
marginal increase in terms of network blocking probability
marginal increase in terms of network blocking probability

IEEE 2014 : NCCloud: A Network-Coding-Based Storage System in a Cloud-of-Clouds
IEEE 2014 Transactions on Computers
Abstract :To provide fault tolerance for cloud storage,
recent studies propose to stripe data across multiple cloud vendors. However,
if a cloud suffers from a permanent failure and loses all its data, we need to
repair the lost data with the help of the other surviving clouds to preserve
data redundancy. We present a proxy-based storage system for fault-tolerant
multiple-cloud storage called NCCloud, which achieves cost-effective repair for
a permanent single-cloud failure. NCCloud is built on top of a
network-coding-based storage scheme called the functional minimum-storage
regenerating (FMSR) codes, which maintain the same fault tolerance and data
redundancy as in traditional erasure codes (e.g., RAID-6), but use less repair
traffic and hence incur less monetary cost due to data transfer. One key design
feature of our FMSR codes is that we relax the encoding requirement of storage
nodes during repair, while preserving the benefits of network coding in repair.
We implement a proof-of-concept prototype of NCCloud and deploy it atop both
local and commercial clouds. We validate that FMSR codes provide significant
monetary cost savings in repair over RAID-6 codes, while having comparable
response time performance in normal cloud storage operations such as
upload/download.

IEEE 2014 : Optimal Power Allocation and Load Distribution for Multiple Heterogeneous Multi core Server Processors across Clouds and Data Centers
IEEE 2014 : Transactions on Computer

IEEE 2014 Transactions on Cloud Computing
Abstract :With cloud storage services, it is commonplace for data to be not only stored in the cloud, but also shared across multiple users. However, public auditing for such shared data — while preserving identity privacy — remains to be an open challenge. In this paper, we propose the first privacy-preserving mechanism that allows public auditing on shared data stored in the cloud. In particular, we exploit ring signatures to compute the verification information needed to audit the integrity of shared data. With our mechanism, the identity of the signer on each block in shared data is kept private from a third party auditor (TPA), who is still able to verify the integrity of shared data without retrieving the entire file. Our experimental results demonstrate the effectiveness and efficiency of our proposed mechanism when auditing shared data.

IEEE 2014 Transactions on Parallel and Distributed Systems

IEEE 2014 Transactions on Parallel and Distributed Systems
Abstract :Software-as-a-Service (SaaS) cloud systems enable application service providers to deliver their applications via massive cloud computing infrastructures. However, due to their sharing nature, SaaS clouds are vulnerable to malicious attacks. In this paper, we present IntTest, a scalable and effective service integrity attestation framework for SaaS clouds. Int Test provides a novel integrated attestation graph analysis scheme that can provide stronger attacker pinpointing power than previous schemes. Moreover, IntTest can automatically enhance result quality by replacing bad results produced by malicious attackers with good results produced by benign service providers. We have implemented a prototype of the IntTest system and tested it on a production cloud computing infrastructure using IBM System S stream processing applications. Our experimental results show that IntTest can achieve higher attacker pinpointing accuracy than existing approaches. IntTest does not require any special hardware or secure kernel support and imposes little performance impact to the application, which makes it practical for large scale cloud systems.

IEEE 2014 : QoS-Aware Data Replication for Data-Intensive Applications in Cloud Computing Systems
Abstract :Cloud computing provides scalable computing and storage resources. More and more data-intensive applications are developed in this computing environment. Different applications have different quality-of-service (QoS) requirements. To continuously support the QoS requirement of an application after data corruption, we propose two QoS-aware data replication (QADR) algorithms in cloud computing systems. The first algorithm adopts the intuitive idea of high-QoS first-replication (HQFR) to perform data replication. However, this greedy algorithm cannot minimize the data replication cost and the number of QoS-violated data replicas. To achieve these two minimum objectives, the second algorithm transforms the QADR problem into the well-known minimum-cost maximum-flow (MCMF) problem. By applying the existing MCMF algorithm to solve the QADR problem, the second algorithm can produce the optimal solution to the QADR problem in polynomial time, but it takes more computational time than the first algorithm. Moreover, it is known that a cloud computing system usually has a large number of nodes. We also propose node combination techniques to reduce the possibly large data replication time. Finally, simulation experiments are performed to demonstrate the effectiveness of the proposed algorithms in the data replication and recovery.

IEEE 2014 : Ensuring Integrity Proof in Hierarchical Attribute Encryption Scheme using Cloud Computing
IEEE 2014 TRANSACTIONS ON CONGITIVE SCIENCE, ENGINEERING AND TECHNOLOGY

IEEE 2014 Transactions on Services Computing
Abstract :With data services in the cloud, users can easily modify and share data as a group. To ensure data integrity can be audited publicly, users need to compute signatures on all the blocks in shared data. Different blocks are signed by different users due to data modifications performed by different users. For security reasons, once a user is revoked from the group, the blocks, which were previously signed by this revoked user, must be re-signed by an existing user. The straightforward method, which allows an existing user to download the corresponding part of shared data and re-sign it during user revocation, is Inefficient due to the large size of shared data in the cloud. In this paper, we propose a novel public auditing mechanism for the integrity of shared data with efficient user revocation in mind. By utilizing proxy re-signatures, we allow the cloud to re-sign blocks on behalf of existing users during user revocation, so that existing users do not need to download and re-sign blocks by themselves. In addition, a public verifier is always able to audit the integrity of shared data without retrieving the entire data from the cloud, even if some part of shared data has been re-signed by the cloud. Experimental results show that our mechanism can significantly improve the efficiency of user revocation.

IEEE 2014 : Attribute-Based Encryption with Verifiable Outsourced Decryption
IEEE 2013 Transactions on Cloud Computing

IEEE 2014 : Enabling Data Dynamic and Indirect Mutual Trust for Cloud Computing Storage Systems
IEEE 2013 Transactions on Cloud Computing
Abstract : Currently, the amount of sensitive data produced by many organizations is
outpacing their storage ability. The management of such huge amount of data is
quite expensive due to the requirements of high storage capacity and qualified
personnel. Storage-as-a-Service (SaaS) offered by cloud service providers
(CSPs) is a paid facility that enables organizations to outsource their data to
be stored on remote servers. Thus, SaaS reduces the maintenance cost and
mitigates the burden of large local data storage at the organization’s end. A
data owner pays for a desired level of security and must get some compensation
in case of any misbehavior committed by the CSP. On the other hand, the CSP needs
a protection from any false accusation that may be claimed by the owner to get
illegal compensations. In this paper, we propose a cloud-based storage scheme
that allows the data owner to benefit from the facilities offered by the CSP
and enables indirect mutual trust between them. The proposed scheme has four important
features: it allows the owner to
outsource sensitive data to a CSP, and perform full block-level dynamic
operations on the outsourced data, i.e., block modification, insertion, deletion,
and append, it ensures that authorized users (i.e., those who have the right to
access the owner’s file) receive the latest version of the outsourced data, it
enables indirect mutual trust between the owner and the CSP, and it allows the
owner to grant or revoke access to the outsourced data. We discuss the security
issues of the proposed scheme. Besides, we justify its performance through
theoretical analysis and experimental evaluation of storage, communication, and
computation overheads.
IEEE 2013 Transactions on Parallel and Distributed Systems
Abstract :With the character of low maintenance, cloud computing provides an economical and efficient solution for sharing group resource among cloud users. Unfortunately, sharing data in a multi-owner manner while preserving data and identity privacy from an untrusted cloud is still a challenging issue, due to the frequent change of the membership. In this paper, we propose a secure multi-owner data sharing scheme, named Mona, for dynamic groups in the cloud. By leveraging group signature and dynamic broadcast encryption techniques, any cloud user can anonymously share data with others. Meanwhile, the storage overhead and encryption computation cost of our scheme are independent with the number of revoked users. In addition, we analyze the security of our scheme with rigorous proofs, and demonstrate the efficiency of our scheme in experiments.

IEEE 2013 :Enabling Data Dynamic and Indirect Mutual Trust for Cloud Computing Storage Systems
IEEE 2013 Transaction on Parallel and Distributed Systems
Abstract :Currently, the amount of sensitive data
produced by many organizations is outpacing their storage ability. The
management of such huge amount of data is quite expensive due to the
requirements of high storage capacity and qualified personnel.
Storage-as-a-Service (SaaS) offered by cloud service providers (CSPs) is a paid
facility that enables organizations to outsource their data to be stored on
remote servers. Thus, SaaS reduces the maintenance cost and mitigates the
burden of large local data storage at the organization’s end. A data owner pays
for a desired level of security and must get some compensation in case of any
misbehavior committed by the CSP. On the other hand, the CSP needs a protection
from any false accusation that may be claimed by the owner to get illegal
compensations. In this paper, we propose a cloud-based storage scheme that
allows the data owner to benefit from the facilities offered by the CSP and
enables indirect mutual trust between them. The proposed scheme has four
important features: it allows the owner to outsource sensitive data to a
CSP, and perform full block-level dynamic operations on the outsourced data,
i.e., block modification, insertion, deletion, and append, it ensures that
authorized users (i.e., those who have the right to access the owner’s file)
receive the latest version of the outsourced data, it enables indirect mutual
trust between the owner and the CSP, and it allows the owner to grant or revoke
access to the outsourced data. We discuss the security issues of the proposed
scheme. Besides, we justify its performance through theoretical analysis and
experimental evaluation of storage, communication, and computation overheads.

IEEE 2014 : Dynamic Resource Allocation using Virtual Machines for Cloud Computing Environment
IEEE 2014 TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS
Abstract : Cloud computing allows business customers to scale up and down their resource usage based on needs. Many of the touted gains in the cloud model come from resource multiplexing through virtualization technology. In this paper, we present a system that uses virtualization technology to allocate data center resources dynamically based on application demands and support green computing by optimizing the number of servers in use. We introduce the concept of “skewness” to measure the unevenness in the multi-dimensional resource utilization of a server. By minimizing skewness, we can combine different types of workloads nicely and improve the overall utilization of server resources. We develop a set of heuristics that prevent overload in the system effectively while saving energy used. Trace driven simulation and experiment results demonstrate that our algorithm achieves good performance.

IEEE 2014 TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS
Abstract : Governments are fac-ing reductions in ICT budgets just as users are increasing demands for electronic services. One solution announced aggressively by vendors is cloud computing. Cloud comput-ing is not a new technology, but as described by Jackson] is a new way of offering services, taking into consideration business and economic models for providing and consuming ICT services. Here we explain the impact and benefits for public organizations of cloud services and explore issues of why governments are slow to adopt use of the cloud. The exist-ing literature does not cover this subject in detail, especially for European organizations

IEEE 2014 TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS
Abstract :Personal health record (PHR) is an emerging patient-centric model
of health information exchange, which is often outsourced to be stored at a
third party, such as cloud providers. However, there have been wide privacy
concerns as personal health information could be exposed to those third party
servers and to unauthorized parties. To assure the patients’ control over
access to their own PHRs, it is a promising method to encrypt the PHRs before
outsourcing. Yet, issues such as risks of privacy exposure, scalability in key
management, flexible access and efficient user revocation, have remained the
most important challenges toward achieving fine-grained, cryptographically
enforced data access control. In this paper, we propose a novel patient-centric
framework and a suite of mechanisms for data access control to PHRs stored in
semi-trusted servers. To achieve fine-grained and scalable data access control
for PHRs, we leverage attribute based encryption (ABE) techniques to encrypt
each patient’s PHR file. Different from previous works in secure data
outsourcing, we focus on the multiple data owner scenario, and divide the users
in the PHR system into multiple security domains that greatly reduces the key
management complexity for owners and users. A high degree of patient privacy is
guaranteed simultaneously by exploiting multi-authority ABE. Our scheme also
enables dynamic codification of access policies or file attributes, supports
efficient on-demand user/attribute revocation and break-glass access under emergency
scenarios. Extensive analytical and experimental results are presented which
show the security, scalability and efficiency of our proposed scheme

IEEE 2013: A Load Balancing Model Based on Cloud Partitioning for the Public Cloud
IEEE TRANSACTIONS ON CLOUD COMPUTING YEAR 2013
Abstract : Load balancing in the cloud computing environment has an important
impact on the performance. Good load balancing makes cloud computing more
efficient and improves user satisfaction. This article introduces a better load
balance model for the public cloud based on the cloud partitioning concept with
a switch mechanism to choose different strategies for different situations. The
algorithm applies the game theory to the load balancing strategy to improve the
efficiency in the public cloud environment. Key words: load balancing model; public cloud;
cloud partition; game theory

IEEE 2013 Transactions on Parallel and Distributed Systems

IEEE 2013 :Attribute-Based Encryption with Verifiable Outsourced Decryption
IEEE 2013 Transactions on Information Forensics and Security

IEEE 2013 Transactions on Parallel and Distributed Systems

IEEE 2013 Transaction on Dependable and Secure Computing
Abstract :Security
challenges are still amongst the biggest obstacles when considering the
adoption of cloud services. This triggered a lot of research activities,
resulting in a quantity of proposals targeting the various cloud security
threats. Alongside with these security issues the cloud paradigm comes with a
new set of unique features which open the path towards novel security
approaches, techniques and architectures. This paper provides a survey on the
achievable security merits by making use of multiple distinct clouds simultaneously.
Various distinct architectures are introduced and discussed according to their
security and privacy capabilities and prospects.

IEEE 2013 Transactions on Innovative Smart Grid

IEEE 2013 Transactions on Knowledge and Data Engineering
Abstract :Current approaches to enforce fine-grained access control on
confidential data hosted in the cloud are based on fine-grained encryption of
the data. Under such approaches, data owners are in charge of encrypting the
data before uploading them on the cloud and re-encrypting the data whenever
user credentials or authorization policies change. Data owners thus incur high
communication and computation costs. A better approach should delegate the
enforcement of fine-grained access control to the cloud, so to minimize the
overhead at the data owners, while assuring data confidentiality from the
cloud. We propose an approach, based on two layers of encryption, that
addresses such requirement. Under our approach, the data owner performs a
coarse-grained encryption, whereas the cloud performs a fine-grained encryption
on top of the owner encrypted data. A challenging issue is how to decompose
access control policies (ACPs) such that the two layer encryption can be
performed. We show that this problem is NP-complete and propose novel
optimization algorithms. We utilize an efficient group key management scheme
that supports expressive ACPs. Our system assures the confidentiality of the
data and preserves the privacy of users from the cloud while delegating most of
the access control enforcement to the cloud.

IEEE 2013 Transactions on Internet Computing
Abstract :The cloud computing paradigm has achieved widespread adoption in recent years. Its success is due largely to customers’ ability to use services on demand with a pay-as-you go pricing model, which has proved convenient in many respects. Low costs and high flexibility make migrating to the cloud compelling. Despite its obvious advantages, however, many companies hesitate to “move to the cloud,” mainly because of concerns related to service availability, data lock-in, and legal uncertainties.1 Lock in is particularly problematic. For one thing, even though public cloud availability is generally high, outages still occur.2 Businesses locked into such a cloud are essentially at a standstill until the cloud is back online. Moreover, public cloud providers generally don’t guarantee particular service level agreements (SLAs)3 — that is, businesses locked into a cloud have no guarantees that it will continue to provide the required quality of service (QoS). Finally, most public cloud providers’ terms of service let that provider unilaterally change pricing at any time. Hence, a business locked into a cloud has no mid- or long term control over its own IT costs.

IEEE 2013 Transaction on Emerging Topics in Computing
Abstract :Large-scale image data sets are being exponentially generated
today. Along with such data explosion is the fast growing trend to outsource
the image management systems to the cloud for its abundant computing resources
and benefits. However, how to protect the sensitive data while enabling
outsourced image services becomes a major concern. To address these challenges,
we propose OIRS, a novel outsourced image recovery service architecture, which
exploits different domain technologies and takes security, efficiency, and
design complexity into consideration from the very beginning of the service
flow. Specifically, we choose to design OIRS under the compressed sensing (CS)
framework, which is known for its simplicity of unifying the traditional
sampling and compression for image acquisition. Data owners only need to
outsource compressed image samples to cloud for reduced storage overhead.
Besides, in OIRS, data users can harness the cloud to securely reconstruct
images without revealing information from either the compressed image samples
or the underlying image content. We start with the OIRS design for sparse data,
which is the typical application scenario for compressed sensing, and then show
its natural extension to the general data for meaningful tradeoffs between
efficiency and accuracy. We thoroughly analyses the privacy-protection of OIRS
and conduct extensive experiments to demonstrate the system effectiveness and
efficiency. For completeness, we also discuss the expected performance speedup
of OIRS through hardware built-in system design. 
IEEE 2014 TRANSACTIONS ON COMPUTERS
Abstract :Using Cloud Storage, users can remotely store their data and enjoy the on-demand high quality applications and services from a shared pool of configurable computing resources, without the burden of local data storage and maintenance. However, the fact that users no longer have physical possession of the outsourced data makes the data integrity protection in Cloud Computing a formidable task, especially for users with constrained computing resources. Moreover, users should be able to just use the cloud storage as if it is local, without worrying about the need to verify its integrity. Thus, enabling public audit ability for cloud storage is of critical importance so that users can resort to a third party auditor (TPA) to check the integrity of outsourced data and be worry-free. To securely introduce an effective TPA, the auditing process should bring in no new vulnerabilities towards user data privacy, and introduce no additional online burden to user. In this paper, we propose a secure cloud storage system supporting privacy-preserving public auditing. We further extend our result to enable the TPA to perform audits for multiple users simultaneously and efficiently. Extensive security and performance analysis show the proposed schemes are provably secure and highly efficient.

IEEE 2014 TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS
Abstract :Storage outsourcing in
cloud computing is a rising trend which prompts a number of interesting
security issues. Provable data possession (PDP) is a method for ensuring the
integrity of data in storage outsourcing. This research addresses the
construction of efficient PDP which called as Cooperative PDP (CPDP) mechanism
for distributed cloud storage to support data migration and scalability of
service, which considers the existence of multiple cloud service providers to
collaboratively store and maintain the clients’ data. Cooperative PDP (CPDP)
mechanism is based on homomorphic verifiable response, hash index hierarchy for
dynamic scalability, cryptographic encryption for security. Moreover, it proves
the security of scheme based on multi-prover zero knowledge proof system, which
can satisfy knowledge soundness, completeness, and zero-knowledge properties.
This research introduces lower computation and communication overheads in
comparison with non-cooperative approaches.
IEEE 2014 : A Gossip Protocol for Dynamic Resource Management in Large Cloud Environments
IEEE 2014 TRANSACTIONS ON NETWORK AND SERVICE MANAGEMENT
Abstract :We address the problem of dynamic resource management for a large-scale cloud environment. Our contribution includes outlining distributed middleware architecture and presenting one of its key elements: a gossip protocol that (1) ensures fair resource allocation among sites/applications, (2) dynamically adapts the allocation to load changes and (3) scales both in the number of physical machines and sites/applications. We formalize the resource allocation problem as that of dynamically maximizing the cloud utility under CPU and memory constraints. We first present a protocol that computes an optimal solution without considering memory constraints and prove correctness and convergence properties. Then, we extend that protocol to provide an efficient heuristic solution for the complete problem, which includes minimizing the cost for adapting an allocation. The protocol continuously executes on dynamic, local input and does not require global synchronization, as other proposed gossip protocols do. We evaluate the heuristic protocol through simulation and find its performance to be well-aligned with our design goals.

Abstract :With the advent of cloud computing, data owners are motivated to outsource their complex data management systems from local sites to the commercial public cloud for great flexibility and economic savings. But for protecting data privacy, sensitive data have to be encrypted before outsourcing, which obsoletes traditional data utilization based on plaintext keyword search. Thus, enabling an encrypted cloud data search service is of paramount importance. Considering the large number of data users and documents in the cloud, it is necessary to allow multiple keywords in the search request and return documents in the order of their relevance to these keywords. Related works on searchable encryption focus on single keyword search or Boolean keyword search, and rarely sort the search results. In this paper, for the first time, we define and solve the challenging problem of privacy-preserving multi-keyword ranked search over encrypted data in cloud computing (MRSE). We establish a set of strict privacy requirements for such a secure cloud data utilization system. Among various multi-keyword semantics, we choose the efficient similarity measure of “coordinate matching,” i.e., as many matches as possible, to capture the relevance of data documents to the search query. We further use “inner product similarity” to quantitatively evaluate such similarity measure. We first propose a basic idea for the MRSE based on secure inner product computation, and then give two significantly improved MRSE schemes to achieve various stringent privacy requirements in two different threat models. To improve search experience of the data search service, we further extend these two schemes to support more search semantics. Thorough analysis investigating privacy and efficiency guarantees of proposed schemes is given. Experiments on the real-world data set further show proposed schemes indeed introduce low overhead on computation and communication

IEEE 2013 : Attribute-Based Encryption with Verifiable Outsourced Decryption
IEEE 2013 TRANSACTIONS ON INFORMATION FORENSICS AND SECURITY
Abstract :Attribute-based encryption (ABE) is a public-key-based one-to-many encryption that allows users to encrypt and decrypt data based on user attributes. A promising application of ABE is flexible access control of encrypted data stored in the cloud, using access polices and ascribed attributes associated with private keys and cipher texts. One of the main efficiency drawbacks of the existing ABE schemes is that decryption involves expensive pairing operations and the number of such operations grows with the complexity of the access policy. Recently, Greenetal. Proposed an ABE system with outsourced decryption that largely elimi-nates the decryption overhead for users. In such a system, a user provides an un trusted server, say a cloud service provider, with a transformation key that allows the cloud to translate any ABE cipher text satisfied by that user’s attributes or access policy into a simple cipher text, and it only incurs a small computational over-head for the user to recover the plaintext from the transformed cipher text. Security of an ABE system with outsourced decryption ensures that an adversary (including a malicious cloud) will not be able to learn anything about the encrypted message; however, it does not guarantee the correctness of the transformation done by the cloud. In this paper, we consider a new requirement of ABE with outsourced decryption: verifiability. Informally, verifiability guarantees that a user can efficiently check if the transformation is done correctly. We give the formal model of ABE with verifiable outsourced decryption and propose a concrete scheme. We prove that our new scheme is both secure and verifiable, without relying on random oracles. Finally, we show an implementation of our
eed introduce low overhead on computation and communication

IEEE 2014 TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS
Abstract : In recent years ad hoc parallel data processing has emerged to be
one of the killer applications for Infrastructure-as-a-Service (IaaS) clouds.
Major Cloud computing companies have started to integrate frameworks for
parallel data processing in their product portfolio, making it easy for
customers to access these services and to deploy their programs. However, the
processing frameworks which are currently used have been designed for static,
homogeneous cluster setups and disregard the particular nature of a cloud.
Consequently, the allocated compute resources may be inadequate for big parts
of the submitted job and unnecessarily increase processing time and cost. In
this paper, we discuss the opportunities and challenges for efficient parallel
data processing in clouds and present our research project Nephele. Nephele is
the first data processing framework to explicitly exploit the dynamic resource
allocation offered by today's IaaS clouds for both, task scheduling and
execution. Particular tasks of a processing job can be assigned to different
types of virtual machines which are automatically instantiated and terminated
during the job execution. Based on this new framework, we perform extended
evaluations of Map Reduce-inspired processing jobs on an IaaS cloud system and
compare the results to the popular data processing framework Hadoop.



No comments:
Post a Comment